 2019-08-10 19:36:03
2019-08-10 19:36:03
允中 发自 凹非寺
编者按:
语言模型的身影遍布在NLP研究中的各个角落,想要了解NLP领域,就不能不知道语言模型。
想要让模型能落地奔跑,就需借助深度学习框架之力,Tensorflow、PyTorch自然是主流,但在Dropout都成独家专利之后,不储备“B计划”,多少让人有些担惊受怕
这里有一份飞桨(PaddlePaddle)语言模型应用实例,从基础概念到代码实现,娓娓道来,一一说明。现在,量子位分享转载如下,宜学习,宜收藏。
刚入门深度学习与自然语言处理(NLP)时,在学习了 Goldberg 特别棒的入门书 NN4NLP,斯坦福 cs224n 等等后,也无限次起念头,写个系列吧,但都不了了之了。
近来,NLP 领域因为超大预训练模型,很多研究需要耗费大量计算资源(比如百度新发布持续学习语义理解框架 ERNIE 2.0,该模型在共计 16 个中英文任务上超越了 BERT 和 XLNet,取得了 SOTA 效果),这样的项目基本上就是在烧钱,小家小户玩不起,于是就傻傻地等着大佬们发出论文,放出代码,刷新榜单。不过这也意味着一个总结的好机会,加上额外的推动,便重新起了念头。
这个系列会介绍我认为现代 NLP 最重要的几个主题,同时包括它们的实现与讲解。
这里会使用的百度的开源深度学习平台飞桨(PaddlePaddle),关于这点,有如下几个原因。
首先,不久前和一个科技媒体朋友聊天,因为当时封锁华为事件的原因,聊到了美国企业是否可能对我们封锁深度学习框架,比如说主流的 Tensorflow 和 Pytorch,我当时答是说不定可能呢,毕竟谷歌连 Dropout 都能去申请专利。只要之后改一下许可,不让使用这些框架的更新,估计我们也没办法,于是就想着可以了解一下国内百度的框架飞桨。
去飞桨的 PaddleNLP 看了一下,内容很丰富,感觉飞桨对 NLP 这块支持非常好,值得关注。
项目地址:
https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP
语言模型
现代 NLP 领域的一个核心便是语言模型 (Language Model),可以说它无处不在,一方面它给 NLP 发展带来巨大推动,是多个领域的关键部分,但另一方面,成也萧何败也萧何,语言模型其实也限制了 NLP 发展,比如说在创新性生成式任务上,还有如何用语言模型获得双向信息。
那到底什么是语言模型?
什么是语言模型

就是语言的模型(认真脸),开个玩笑,语言模型通俗点讲其实就是判断一句话是不是人话,正式点讲就是计算一句话的概率,这个概率值表示这个本文有多大概率是一段正常的文本。
对于一句话,比如说用脸滚出来的一句话:“哦他发看和了犯点就看见发”,很明显就不像人话,所以语言模型判断它是人话的概率就小。而一句很常用的话:“好的,谢谢”,语言模型就会给它比较高的概率评分。
用数学的方式来表示,语言模型需要获得这样的概率:
其中 X 表示句子,x1,x2… 代表句子中的词。怎么计算这样一个概率呢,一个比较粗暴的方法就是有个非常非常大的语料库,里面有各种各样的句子,然后我们一个个数,来计算不同句子的概率,但稍微想想就知道这个方法不太可能,因为句子组合无穷无尽。
为更好计算,利用条件概率公式和链式法则,按照从左到右的句序,可以将公式转换成:
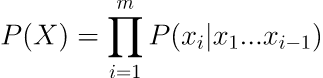
题变成了如何求解:
怎么根据前面所有的词预测下一个词,当然这个问题对于现在还有点复杂,之后可以用 RNN 模型来计算,但现在让我们先假设对于一个词离它近的词重要性更大,于是基于马尔可夫性假设,一个词只依赖它前面 n-1 个词,这种情况下的语言模型就被称为 N-gram 语言模型。
比如说基于前面2个词来预测下一个词就是 3-gram (tri-gram) 语言模型:
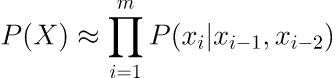
细心些的话,会发现,当 n-gram 中的 n 增大,就会越接近原始语言模型概率方程。
当然n并不是越大越好,因为一旦n过大,计算序列就会变长,在计算时 n-gram 时词表就会太大,也就会引发所谓的 The Curse of Dimension (维度灾难) 。因此一般大家都将n的大小取在3,4,5附近。
早期实现:数一数就知道了
最早了解类似语言模型计算概率,是在研究生阶段当时号称全校最难的信息论课上,老师强烈安利香农的经典论文 A Mathematical Theory of Communication,论文中有一小节中,他就给利用类似计算上述语言模型概率的方法,生成了一些文本。

其中一个就是用 2-gram (bi-gram) 的频率表来生成的,这已经相当于一个 bi-gram 语言模型了。

同样,要构建这样一个 n-gram 语言模型,最主要工作就是,基于大量文本来统计 n-gram 频率。
当时有个课程作业,就是先准备一些英文文本,然后一个一个数 n-gram,之后除以总数算出语言模型中需要的概率估计值,这种方法叫 Count-based Language Model。
传统 NLP 中搭建语言模型便是这样,当然还有更多技巧,比如平滑算法,具体可以参考 Jurafsky 教授的书和课。
但这种方法会有一个很大的问题,那就是前面提到的维度灾难,而这里要实现的神经网络语言模型(Neural Network Language Model),便是用神经网络构建语言模型,通过学习分布式词表示(即词向量)的方式解决了这个问题。
语言模型能干什么
不过在谈神经网络语言模型前,我们先来看看语言模型的用途。
那它有什么用呢,如之前提到,语言模型可以说是现代 NLP 核心之一,无处不在。比如说词向量,最早算是语言模型的副产品;同时经典的序列到序列(seq2seq) 模型,其中解码器还可以被称为,Conditional Language Model(条件语言模型);而现在大火的预训练模型,主要任务也都是语言模型。
在实际 NLP 应用中,我认为能总结成以下三条:
第一,给句子打分,排序。先在大量文本上训练,之后就能用获得的语言模型来评估某句话的好坏。这在对一些生成结果进行重排序时非常有用,能很大程度地提高指标,机器翻译中有一个技巧便是结合语言模型 Loss 来重排序生成的候选结果。
第二,用于文本生成。首先其训练方式是根据前面词,生成之后词。于是只要不断重复此过程(自回归)就能生成长文本了。比较有名的例子就包括最近的 GPT2,其标题就叫 “ Better Language Models and Their Implications.” 它生成的句子效果真的非常棒,可以自己体验一番 https://talktotransformer.com/.

第三,作为预训练模型的预训练任务。最近很火的预训练模型,几乎都和语言模型脱不开关系。
比如说 ELMo 就是先训练双向 LSTM 语言模型,之后双向不同层向量拼接获得最后的 ELMo词向量,还有 BERT 里最主要的方法就是 Masked Language Model (遮掩语言模型)。
而最近的 XLNet 中最主要训练任务也叫做 Permutation language Model (排列语言模型),可见语言模型在其中的重要性重要性。
神经网络语言模型架构
接下来简单介绍一下这里要实现的网络结构,借鉴自 Bengio 的经典论文 A Neural Probabilistic Language Model 中的模型。

这里我们训练 Tri-gram语言模型,即用前面两个词预测当前词。
于是输入就是两个单词,然后查表取出对应词向量,之后将两个词向量拼接起来,过一个线性层,加入 tanh 激活函数,最后再过线性层输出分数,通过 softmax 将分数转换成对各个词预测的概率,一般取最大概率位置为预测词。
用公式表达整个过程就是:
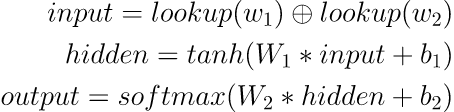
整个结构非常简单,接下来就来看看如何用 飞桨来实现这个结构吧,同时介绍以下 飞桨的基本思想,和一般训练流程。
项目地址:
https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/language_model
PaddlePaddle代码基本实现
这里拿一个小例子来解说,假设我们在一个叫做 PaddlePaddle 的世界,这个世界的人们只会说三句话,每句话三个词,我们需要建立一个 Tri-gram 语言模型,来通过一句话前两个词预测下一个词。
关于整个流程,主要分成准备,数据预处理,模型构建,训练,保存,预测几个阶段,这也是一般一个 NLP 任务的基础流程。
准备
首先,先导入需要的库。
importnumpy asnp
importpaddle
importpaddle.fluid asfluid
之后准备训练数据与词表,统计所有不同词,建立词表,然后按照顺序建立一个单词到 id 的映射表和配套的 id 到单词映射表。因为模型无法直接读这些词,所以需要单词与 id 之间的转换。
# 假设在这个叫做Paddle的世界里,人们只会说这三句话
sentences = [ "我 喜欢 Paddle", "Paddle 等于 飞桨", "我 会 Paddle"]
vocab = set( ' '.join(sentences).split( ' ')) # 统计词表
word2idx = {w: i fori, w inenumerate(word_list)} # 建立单词到id映射表
idx2word = word_list # id到单词的映射表
n_vocab = len(word2idx) # 词表大小
准备好数据后,设置模型参数和训练相关参数,因为任务很简单,所以参数都设很小。
# 参数设置
# 语言模型参数
n_step = 2# 输入前面多少个词,tri-gram 所以取 3-1=2 个
n_hidden = 2# 隐层的单元个数
# 训练参数
n_epochs = 5000# 训练 epoch 数
word_dim = 2# 词向量大小
lr = 0.001# 学习率
use_cuda = False#用不用GPU
数据预处理
根据 PaddlePaddle 数据输入要求,需要准备数据读取器 (reader),之后通过它来读取数据,对输入数据进行一些前处理,最后作为 batch 输出。
defsent_reader:
defreader:
batch = []
forsent insentences:
words = sent.split( ' ')
input_ids = [word2idx[word] forword inwords[: -1]] # 将输入转为id
target_id = word2idx[words[ -1]] # 目标转为id
input = np.eye(n_vocab)[input_ids] # 将输入id转换成one_hot表示
target = np.array([target_id])
batch.append((input, target))
yieldbatch
returnreader
构建模型
这里从飞桨中较底层 API 来进行构建,理解更透彻。先创建所需参数矩阵,之后按照前面的公式来一步步运算。
defnnlm(one_hots):
# 创建所需参数
# 词向量表
L = fluid.layers.create_parameter(shape=[n_vocab, word_dim], dtype= 'float32')
# 运算所需参数
W1 = fluid.layers.create_parameter(shape=[n_step*word_dim, n_hidden], dtype= 'float32')
b1 = fluid.layers.create_parameter(shape=[n_hidden], dtype= 'float32', is_bias= True)
W2 = fluid.layers.create_parameter(shape=[n_hidden, n_vocab], dtype= 'float32')
b2 = fluid.layers.create_parameter(shape=[n_vocab], dtype= 'float32', is_bias= True)
# 取出词向量
word_emb = fluid.layers.matmul(one_hots, L)
# 两个词向量拼接
input = fluid.layers.reshape(x=word_emb, shape=[ -1, n_step*word_dim], inplace= True)
# 前向运算
input2hid = fluid.layers.tanh(fluid.layers.matmul(input, W1) + b1) # 输入到隐层
hid2out = fluid.layers.softmax(fluid.layers.matmul(input2hid, W2) + b2) # 隐层到输出
returnhid2out
先根据输入的独热(one-hot)向量,取出对应的词向量,因为每个例子输入前两个词,因此每个例子可获得两个词向量,之后按照步骤,将它们拼接起来,然后与 W1 和 b1 进行运算,过 tanh 非线性,最后再拿结果与 W2 和 b2 进行运算,softmax 输出结果。
接下来构建损失函数,我们用常用的交叉熵(cross-entropy)损失函数,直接调 API。
defce_loss(softmax, target):
cost = fluid.layers.cross_entropy(input=softmax, label=target) # 计算每个batch的损失
avg_cost = fluid.layers.mean(cost) # 平均
returnavg_cost
开始训练
终于进入了训练环节,不过为了更好理解,先稍稍介绍一点 飞桨的设计思想。
飞桨同时为用户提供动态图和静态图两种计算图。动态图组网更加灵活、调试网络便捷,实现AI 想法更快速;静态图部署方便、运行速度快,应用落地更高效。
如果想了解飞桨动态图更多内容,可以参考GitHub项目地址:https://github.com/PaddlePaddle/models/tree/v1.5.1/dygraph
实际应用中,静态图更为常见,下面我们以静态图为例介绍一个完整的实现:
首先,需要先定义 Program,整个 Program 中包括了各种网络定义,操作等等,定义完之后,再创建一个 Executor 来运行 Program,用过类似框架的同学应该并不陌生。
因此先来看看这两行代码,fluid 中最重要的两个 Program,将它们取出来。
startup_program = fluid.default_startup_program # 默认启动程序
main_program = fluid.default_main_program # 默认主程序
default_startup_program 主要定义了输入输出,创建模型参数,还有可学习参数的初始化;而 default_main_program 则是定义了神经网络模型,前向反向,还有优化算法的更新。
之后将之前定义好的一些模块放入训练代码中。
train_reader = sent_reader # 获取数据 reader
# 定义输入和目标数据
input = fluid.layers.data(name= 'input', shape=[ -1, n_step, n_vocab], dtype= 'float32')
target = fluid.layers.data(name= 'target', shape=[ -1, 1], dtype= 'int64')
# 输入到模型,获得 loss
softmax = nnlm(input)
loss = ce_loss(softmax, target)
之后还需要定义优化器(Optimizer),还有数据 Feeder 用于喂入数据。
# 配置优化器
optimizer = fluid.optimizer.Adam(learning_rate= 0.001) # 万金油的 Adam
optimizer.minimize(loss)
# 用于之后预测
prediction = fluid.layers.argmax(softmax, axis= -1)
# 定义 Executor
place = fluid.CUDAPlace( 0) ifuse_cuda elsefluid.CPUPlace # 指定运行位置
exe = fluid.Executor(place)
#定义数据 Feeder
feeder = fluid.DataFeeder(feed_list=[input, target], place=place) # 每次喂入input和target
至此就完成了第一步的定义环节,然后就可以用定义的 Executor 来执行程序了。
# 参数初始化
exe.run(startup_program)
# 训练
forepoch inrange(n_epochs):
fordata intrain_reader:
metrics = exe.run(
main_program, # 主程序
feed=feeder.feed(data), # 数据喂入
fetch_list=[loss]) # 要取出的数据
ifepoch % 500== 0:
print( "Epoch {}, Cost {:.5f}".format(epoch, step, float(metrics[ 0][ 0])))
简单解释一下代码,训练时需要exe.run来执行每一步的训练,对于run需要传入主程序,还有输入 Feeder,和需要拿出来(fetch)的输出。
之后运行就能看到训练 log 了。

能明显看到 loss 在不断下降,等训练完成,我们就获得一个训练好的模型。
保存模型
在预测前可以尝试先保存一个模型,可以便于之后使用,比如 load 出来做预测。
fluid.io.save_inference_model( './model', [ 'input'], [prediction], exe)
很简单,只需要传入保存的路径’./model’,预测需要 feed 的数据’input’,之后需要 fetch 出的预测结果 prediction,最后加上执行器 exe,就 OK 了。
非常快。
预测阶段
预测阶段其实和训练阶段类似,但因为主程序都保存下来了,所以只用先建立执行器 Executor,同时建立一个用于预测的作用域。
infer_exe = fluid.Executor(place) # 预测 Executor
inference_scope = fluid.core.Scope # 预测作用域
然后在预测作用域中 load 出模型,进行预测运算,大部分操作都和训练很类似了。唯一不同就是 load 模型这块,其实就是把之前保存下来的参数给 load 出来了,然后用于预测。
withfluid.scope_guard(inference_scope):
[inference_program, feed_target_names,
fetch_targets] = fluid.io.load_inference_model( './model', infer_exe) # 载入预训练模型
infer_reader = sent_reader # 定义预测数据 reader
infer_data = next(infer_reader) # 读出数据
infer_feat = np.array([data[ 0] fordata ininfer_data]).astype( "float32")
assertfeed_target_names[ 0] == 'input'
results = infer_exe.run(inference_program,
feed={feed_target_names[ 0]: infer_feat},
fetch_list=fetch_targets) # 进行预测
结果如何?
forsent, idx inzip(sentences, results[ 0]):
print( "{} -> {}".format( ' '.join(sent.split[: 2]), idx2word[idx]))
我 喜欢 -> Paddle
Paddle 等于 -> 飞桨
我 会 -> Paddle
模型完美地学习到了 PaddlePaddle 世界中仅有的几个 trigram 规则,当然因为该任务非常简单,所以模型一下就能学会。
更多尝试
在了解完以上这个小例子之后,就能在它基础上做很多修改了,感兴趣的同学不妨拿下面的几个思路作为练习。
比如说用一个大数据集,加上更大模型,来进行训练,可以尝试复现 Bengio 论文中的模型规模,大致结构差不多,只是修改一下参数大小。
还比如说,在这里搭建网络结构时,用的是较底层API,直接创建矩阵权重,相乘相加,而 飞桨中有很多好用的API,能否调用这些API来重新构建这个模型呢,比如说词向量部分,可以用fluid.layers.embedding直接传入词 id 来实现,还有全连接层,可以直接用 fluid.layers.fc 来实现,激活函数可以直接通过里面参数设置,非常方便。
其实还可以在这里尝试些小技巧,比如共享词向量表为 softmax 前全连接层的权重 W2,以及加入 Bengio 论文中提到的类似残差连接直接将 embedding 连到输出的部分。
这次在这里介绍神经网络语言模型,并通过 飞桨来实现了一个简单的小例子,主要想做的是:
第一,语言模型任务在 NLP 领域很重要,想首先介绍一下;
第二,Bengio 这篇神经网络语言模型的论文非常经典,比如说提出了用神经网络实现语言模型,同时还最早提出词表示来解决“维数灾难”问题,通过复现,也好引出之后词向量,还有seq2seq 等话题;
第三,通过用 飞桨来实现这样一个简单例子,可以抛开各种模型与数据复杂度,更直观了解一个飞桨程序是如何构建的,也为之后讲解飞桨更复杂程序打下基础。
想详细了解更多飞桨相关内容,请点击文末阅读原文或参阅以下链接:












