 2019-08-18 11:17:15
2019-08-18 11:17:15
概述
您可能有大量应用程序产生的JSON数据,您可能需要对这些JSON数据进行整理,去除不想要的字段,或者只保留想要的字段,或者仅仅是进行数据查询。
那么,利用阿里云Data Lake Analytics或许是目前能找到的云上最为便捷的达到这一目标的服务了。仅仅需要3步,就可以完成对海量JSON数据的处理,或者更为复杂的ETL流程。
第一步:JSON数据到阿里云OSS
利用各种手段,将JSON数据投递到OSShttps://www.aliyun.com/product/oss)中。
通常,对于云上日志链路,还有一种JSON到OSS的投递链路,可以参考“云原生日志数据分析上手指南”其中的JSON部分。
第二步:DLA中建表
参考上述“云原生日志数据分析上手指南”,其中已经有海量JSON数据的分区模式建表方法了。本例中,以非分区表为例,假设,数据文件中每一行一个JSON数据,JSON数据放置的OSS路径为:

则,在DLA中执行建表:

第三步:利用DLA JSON函数SQL处理
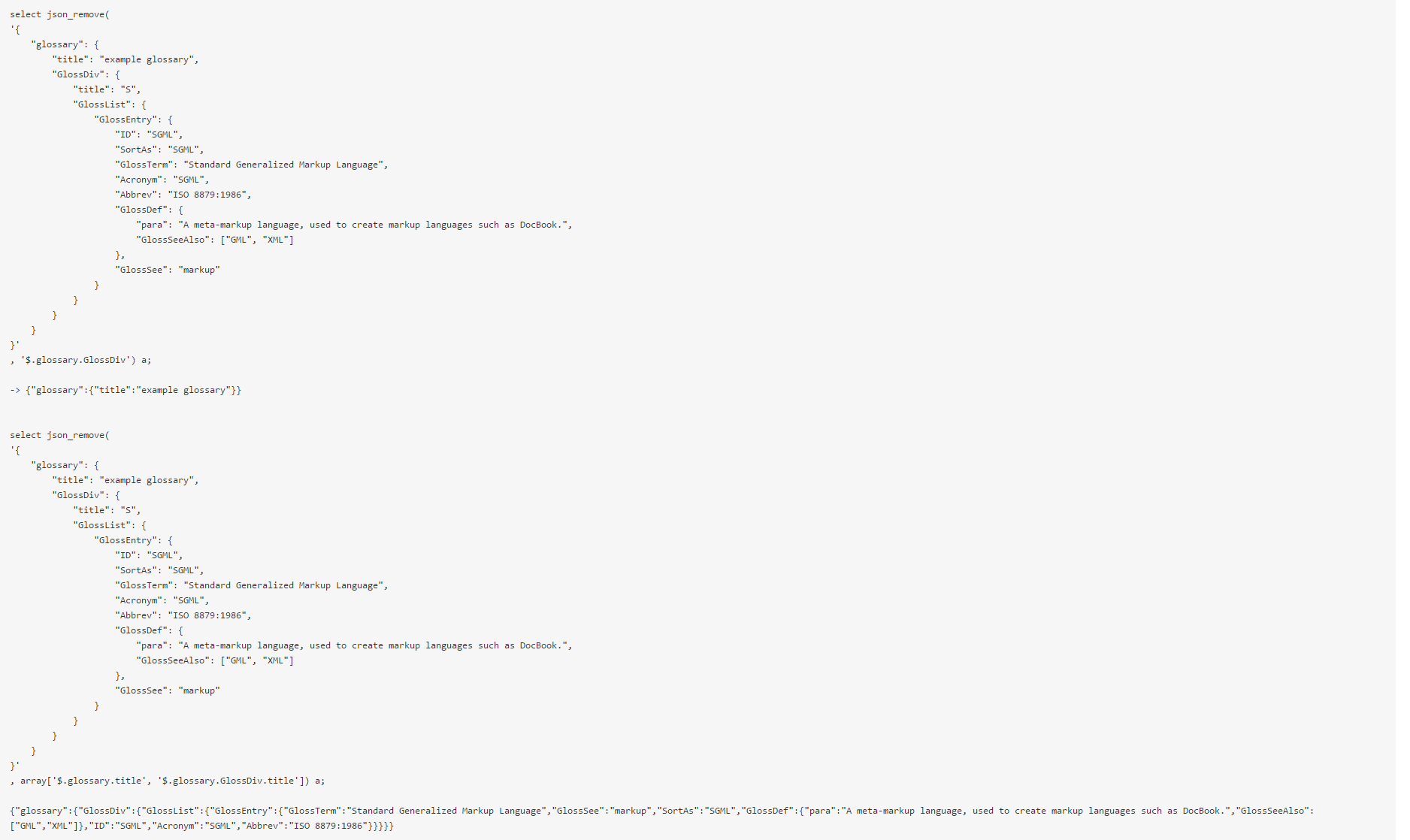
json_remove
从JSON中去除指定JSON Path的数据。可以一次处理一个JSON path,也可以一次处理多个JSON path。注意:目前还不支持“..”等JSON path的模糊匹配,不久后会支持。

示例:
json_reserve
从JSON中保留指定JSON Path的数据,去除其他的数据。可以一次处理一个JSON path,也可以一次处理多个JSON path。注意:目前还不支持“..”等JSON path的模糊匹配,不久后会支持。

示例:

后记
还可以利用Data Lake Analytics强大的云上数据处理能力,进行多源数据融合处理、分析,回流到其他数据库、存储系统中。
更多信息请参考:https://datalakeanalytics.console.aliyun.com/overview
-----------------------------------
本文作者:Roin












