 2020-11-25 13:02:02
2020-11-25 13:02:02
机器之心发布
机器之心编辑部
快手商业化进程开始加速,这对底层计算能力提出挑战。快手决定将 GPU 推理在商业化场景全量落地。
据官方披露,快手日活已超 3 亿,直播日活达 1.7 亿 +,快手之夜单场活动快手官方直播间累计观看总人数就超过 9000 万。随着业务规模的不断扩张,快手商业化进程也随之加速,单场直播最高成交额 12.5 亿,8 月电商订单总量达 5 亿。巨大的商业价值和潜力吸引越来越多的广告主来到快手做营销。为了应对日益激增的营销素材,快手不断提升底层计算能力,率先将 GPU 推理应用到大规模稀疏场景中,在提高机器性能、节约成本的同时,为广告主提供了更加有效的营销效果。
2019 年开始,快手商业化进程开始加快,底层计算能力持续面临挑战:
- 一方面,随着业务的发展,业务形态越来越丰富,流量越来越高,广告主对推荐质量的要求越来越高,模型变宽变深,算力的消耗急剧增加;
- 另一方面,在广告推荐场景下主要使用 DNN 模型,涉及大量稀疏特征 embedding 和神经网络浮点运算。作为访存和计算密集型的线上服务,在保证可用性的前提下,要满足低延迟、高吞吐的要求,对单机算力也是一种挑战。
上述算力资源需求和空间的矛盾,如果不解决好,对业务的发展会带来很大的限制:在模型加宽加深前,纯 CPU 推理服务能够提供可观的吞吐,但是在模型加宽加深后,计算复杂度上升,为了保证可用性,需要消耗大量机器资源,导致大模型无法大规模应用于线上。
目前行业比较通用的解决办法是利用 GPU 来解决这个问题。GPU 本身比较适合高吞吐、对延迟不太敏感的计算任务,在业界应用中,主要用于图像、语音或者离线训练等场景。
对于推荐、广告等场景使用的大规模稀疏模型,我们需要解决如下挑战:如何在保证可用性、低延迟的前提下,尽可能做到高吞吐,同时还需要考虑易用性和通用性。
业内一般会使用 TensorFlow 进行训练,在 GPU 场景推理时,则会选择 TensorFlow 或 TensorRT。对于 TensorFlow 和 TensorRT 的结合,常见的做法是利用开源工具离线将 TensorFlow 模型转换到 ONNX 模型,然后从 ONNX 模型加载,这引入了更多的中间环节,当 ONNX 不支持 TensorFlow 的某些 Op 时,转换会失败。这限制了模型的结构,也导致训练好的 TensorFlow 模型无法直接以端到端的形式应用于线上。
快手借鉴业界经验,从实际业务出发,围绕大规模稀疏模型场景,针对发挥 GPU 算力和 TensorFlow 与 TensorRT 的结合易用性,进行了一系列技术上的探索和尝试。
融合 CPU、GPU 各自硬件优势
快手在硬件部署时就充分考虑了硬件特点,融合不同硬件的优势。在广告推理场景下,CPU 适合大规模稀疏特征 embedding 访存密集型任务,GPU 适合进行 DNN 这种大规模浮点运算的计算密集型任务,以此实现 CPU 和 GPU 的高效率配合。
于是,快手从多个业务的推理服务中选取典型的服务,简化场景,提炼出核心计算过程,尝试不同的 GPU 卡进行压测,综合考虑硬件的特性、成本以及业务的发展情况,确定机型,对齐算力需求和硬件能力。
保证易用性,实现训练到推理端到端
结合 Tensorflow 的高可扩展性和 TensorRT 的高性能,快手在线进行 TensorFlow 模型到 TensorRT 模型的转换,基于 TensorRT 推理专用引擎的高性能,加速 DNN 计算,保持 TensorFlow 模型的训练和在线推理以端到端方式进行。
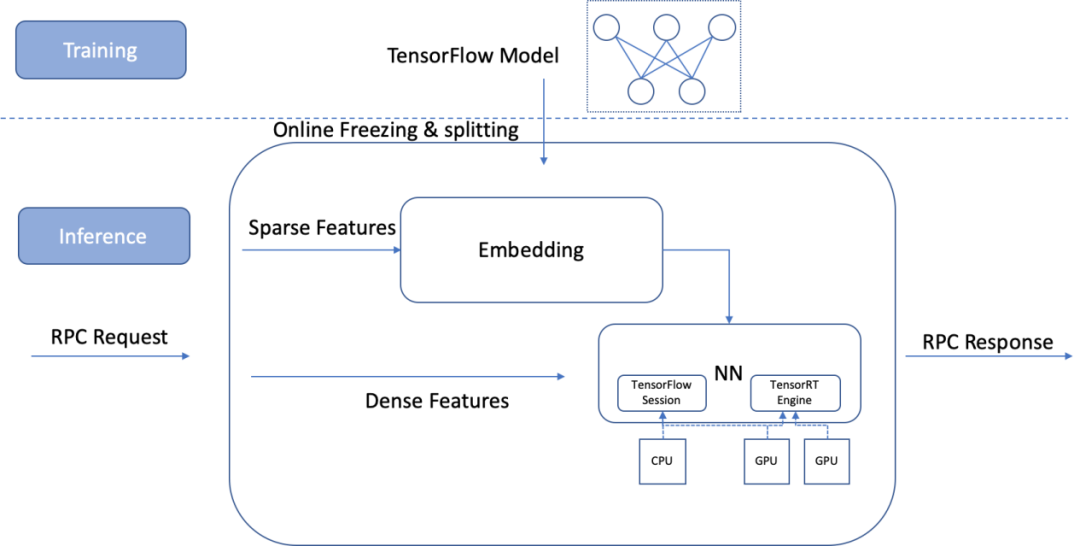
图 1. Predict Server 的模型加载和计算流程
计算流水优化,提升硬件利用率
快手利用多 cuda stream,同时运行多个 Compute Engine,增加 GPU 有效工作时间的占比,使每个 Compute Engine 对应两条 Cuda stream,优化了 H2D 数据传输到 GPU 计算的流水:
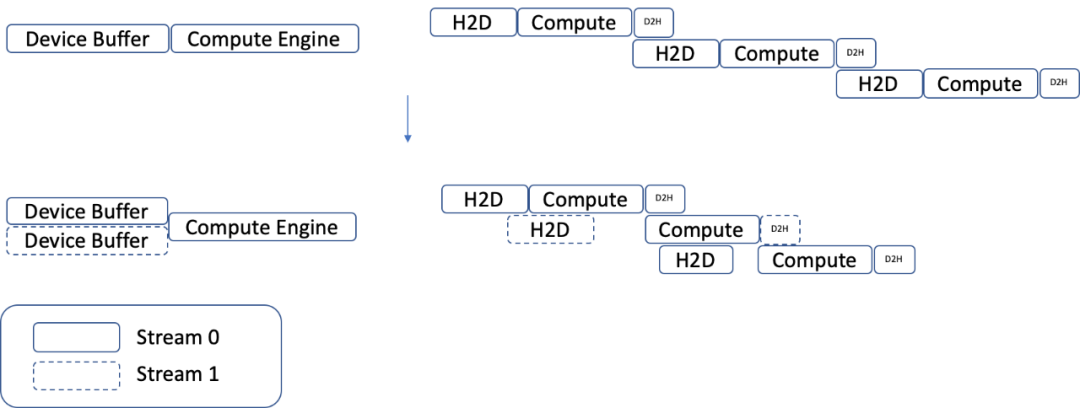
图 2. 多 Cuda Stream、Compute Engine 和计算流水优化
自动对 TF graph 做裁剪,减少重复计算和内存拷贝,不断优化 CPU 到 GPU 的流水(比如对 user 侧 embedding 在卡上展开),达到算力均衡。
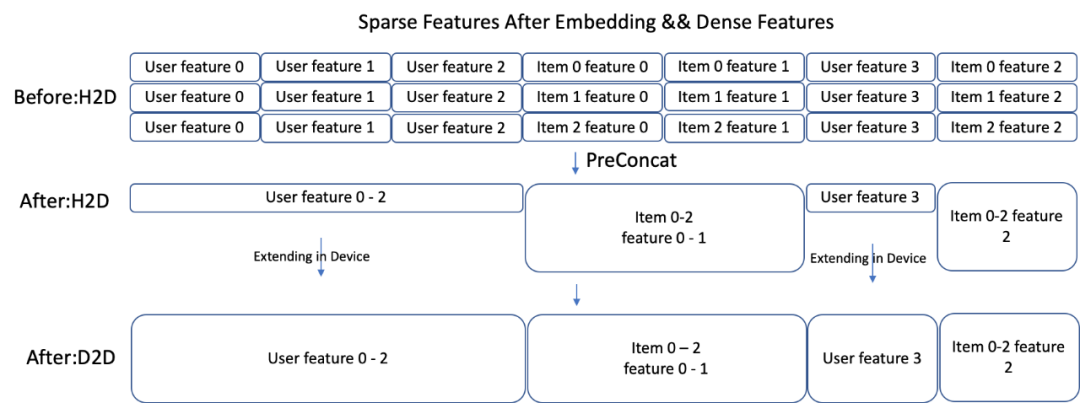
图 3. User 特征的 GPU 展开
灵活配置,降低成本提升集群算力
为了降低每块卡的单机成本,快手采用单机双卡的机型,基于容器化隔离硬件资源,实现灵活分配。为了提高资源的利用率,快手通过 docker 将一台 GPU 服务器虚拟化为 2 个实例,通过 cpu manager 降低跨核心调度导致的性能损耗,进而保障服务容器化后的稳定性和性能。
对于大规模稀疏场景,模型占比中较大的是 EmbeddingTable,可能达到 TB 级规模,单机内存无法容纳,所以一般会将部分的 EmbeddingTable 以哈希的形式打散并保存在其他分布式节点上,在线推理时再通过稀疏的特征拉取参数。但带宽放大明显往往最先成为瓶颈,极大地限制了 Predict server(GPU 节点)算力的发挥。
结合场景和模型的特点,快手也进行了针对性的设计和优化。
在推荐广告场景中,每次请求针对一个 User 和 N 个 Item 进行预估。如果将 Item 的特征放在分布式节点上进行 embedding 计算,单次的数据通信量相较 User 特征会被放大 N 倍,通信带宽会成为 Predict Server 和 Emp Server(分布式计算节点)之间的瓶颈。
快手将 User 特征的 EmbeddingTable 和 Reduce sum 运算放在 Emp server 上,一方面可以利用相对廉价的 CPU 资源分担内存和算力需求,另一方面 User 特征不存在网络通信放大的问题,对带宽的压力要小得多。而将 DNN 等浮点数运算密集的逻辑保留在 PredictServer(GPU 节点)上,这能够充分利用 CPU 节点,结合 CPU 和 GPU 的优势,保证大规模模型的线上应用。
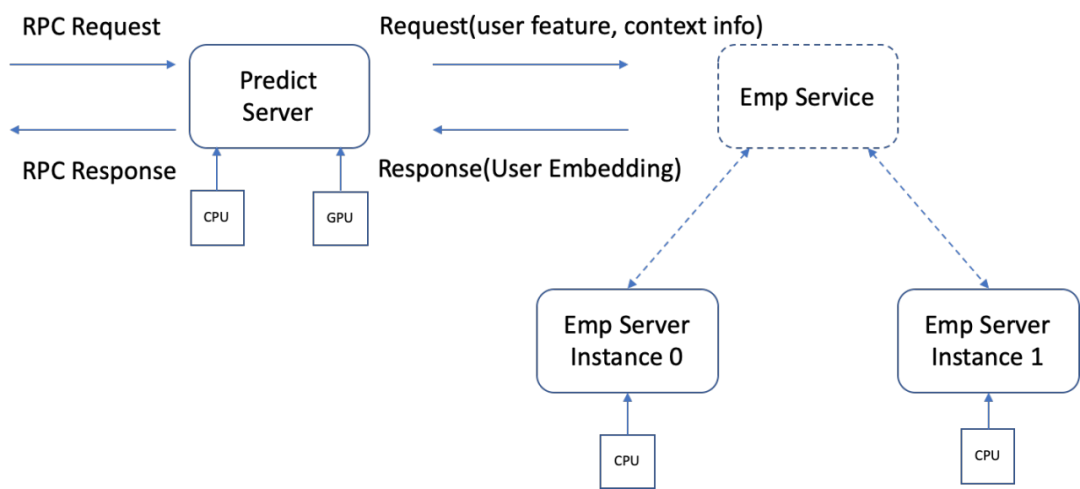
图 4. 分布式 Predict Server
2020 年,GPU 在快手商业化在线服务中实现了 0-1 的突破,GPU 在商业化在线推理服务中全面落地,形成 CPU 和 GPU 的混合集群,根据算力需求匹配机器,实现机器成本优化约 20~30%,在成本不变的情况下,为广告主提供更加高质量的营销体验和收益。












