 2019-08-10 09:38:07
2019-08-10 09:38:07
本文介绍对于 BERT 的 Pretraining 过程进行改进的几篇文章,包括 Pre-Training with Whole Word Masking for Chinese BERT、ERNIE: Enhanced Representation through Knowledge Integration 和 ERNIE 2.0: A Continual Pre-training Framework for Language Understanding。
注意:这几篇文章都是对 BERT 模型的 Pretraining 阶段的 Mask 进行了不同方式的改进,但是对于 BERT 模型本身(基于 Mask LM 的 Pretraining、Transformer 模型和 Fine-tuning)没有做任何修改。
因此对于不需要 Pretraining 的用户来说,只要把 Google 提供的初始模型替换成这些模型就可以直接享受其改进了(百度的 ERNIE 和 ERNIE 2.0 是基于 PaddlePaddle 的,TensorFlow 和 PyTorch 用户需要借助第三方工具进行转换)。
阅读本文前,读者需要了解 BERT 的基本概念,不熟悉的读者可以先学习 BERT 课程[1]、BERT 模型详解 [2]和 BERT 代码阅读 [3]。
Whole Word Masking

基本思想
注:虽然我这里介绍的是哈工大与科大讯飞的论文 Pre-Training with Whole Word Masking for Chinese BERT,但是 Whole Word Mask 其实是 BERT 的作者提出来的。他们并没有发论文,因为这是一个很简单(但是很有效)的改进。
由于中文的特殊性,BERT 并没有提供中文版的 Pretraining 好的 Whole Word Masking 模型。中文版的 Pretraining Whole Word Masking 模型可以在这里下载:
https://github.com/ymcui/Chinese-BERT-wwm
为了解决 OOV 的问题,我们通常会把一个词切分成更细粒度的 WordPiece(不熟悉的读者可以参考机器翻译 · 分词[4] 和 WordpieceTokenizer [5])。BERT 在 Pretraining 的时候是随机 Mask 这些 WordPiece 的,这就可能出现只 Mask 一个词的一部分的情况,比如下面的例子:

▲ 图. Whole Word Mask模型的示例
probability 这个词被切分成 ”pro”、”#babi” 和 ”#lity”3 个 WordPiece。有可能出现的一种随机 Mask 是把 ”#babi” Mask 住,但是 ”pro”和”#lity” 没有被 Mask。这样的预测任务就变得容易了,因为在”pro”和”#lity”之间基本上只能是”#babi”了。这样它只需要记住一些词(WordPiece 的序列)就可以完成这个任务,而不是根据上下文的语义关系来预测出来的。
类似的中文的词”模型”也可能被 Mask 部分(其实用”琵琶”的例子可能更好,因为这两个字只能一起出现而不能单独出现),这也会让预测变得容易。
为了解决这个问题,很自然的想法就是词作为一个整体要么都 Mask 要么都不 Mask,这就是所谓的 Whole Word Masking。这是一个很简单的想法,对于 BERT 的代码修改也非常少,只是修改一些 Mask 的那段代码。对于英文来说,分词是一个(相对)简单的问题。哈工大与科大讯飞的论文对中文进行了分词,然后做了一些实验。
实现细节
数据预处理
训练数据来自 Wiki 的中文 dump [6],使用 WikiExtractor.py [7]对 Wiki 进行抽取,总共得到 1,307 个文件。这里同时使用了简体和繁体中文的 Wiki 文章。对网页进行抽取和处理之后得到 13.6M 行的文本。中文分词使用的是哈工大 LTP [8]。分完词后使用 BERT 官方代码提供的 create_pretraining_data.py 来生成训练数据,没有做任何修改(包括 Mask 的比例)。
Pretraining
Whole Word Masking 可以看做是对原来 BERT 模型的一个改进,一种增加任务难度的方法,因此我们并不是从头开始 Pretraining,而是基于原来 Google 发布的中文模型继续训练的(我感觉另外一个原因就是没有那么多计算资源从头开始)。
这里使用了 batch 大小为 2,560,最大长度为 128 训练了 100k 个 steps,其中初始的 learning rate 是 1e-4 (warm-up ratio 是 10%)。然后又使用最大长度为 512(batch 大小改小为 384)训练了 100k 个 steps,这样让它学习更长距离的依赖和位置编码。
BERT 原始代码使用的是 AdamWeightDecayOptimizer,这里换成了 LAMB 优化器,因为它对于长文本效果更好。
Fine-tuning
Fine-tuning 的代码不需要做任何修改,只不过是把初始模型从原来的基于 WordPiece 的 Pretraining 的模型改成基于 Whole Word Masking 的 Pretraining 模型。
实验结果
阅读理解任务
实验了 CMRC 2018、DRCD 和 CJRC,结果如下。
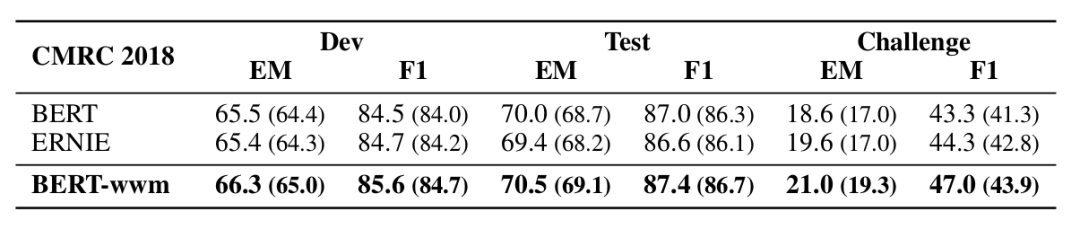
▲ 图. CMRC 2018数据集上的实验结果
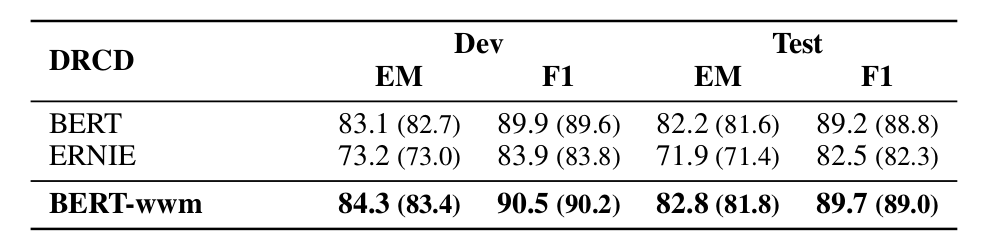
▲ 图. DRCD数据集上的实验结果
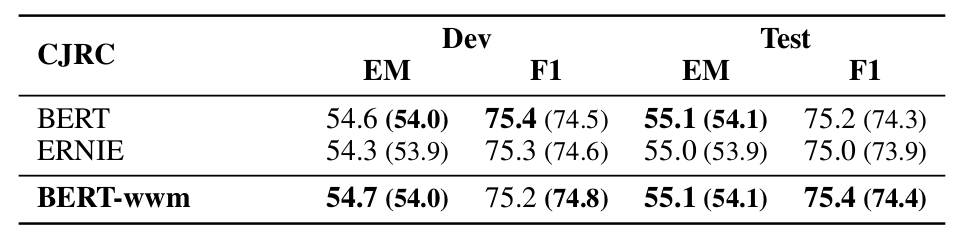
▲ 图. CJRC数据集上的实验结果
命名实体识别任务
在人民日报(People Daily)和微软亚研究院 NER (MSRA-NER) 数据集做了实验,结果如下。

▲ 图. NER任务的实验结果
自然语言推理 (Natural Language Inference)
对于自然语言推理任务 XNLI 中的中文数据进行了实验,结果如下。

▲ 图. XNLI中文数据集的实验结果图
情感分类 (Sentiment Classification)
在 ChnSentiCorp 和 Sina Weibo 两个数据集上的实验结果如下。
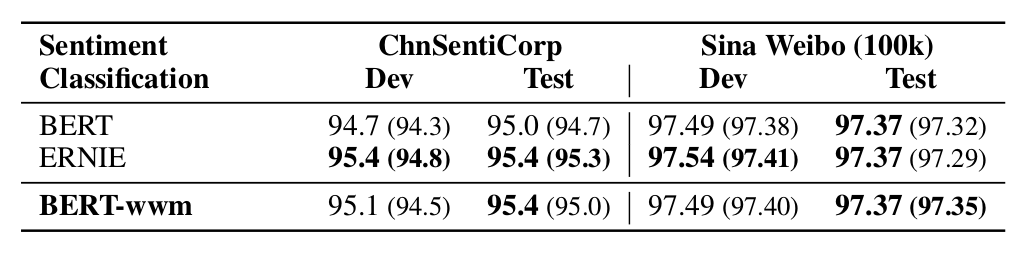
▲ 图. 情感分类任务的实验结果
句对匹配 (Sentence Pair Matching)
在 LCQMC 和 BQ Corpu 数据集上的实验结果为:
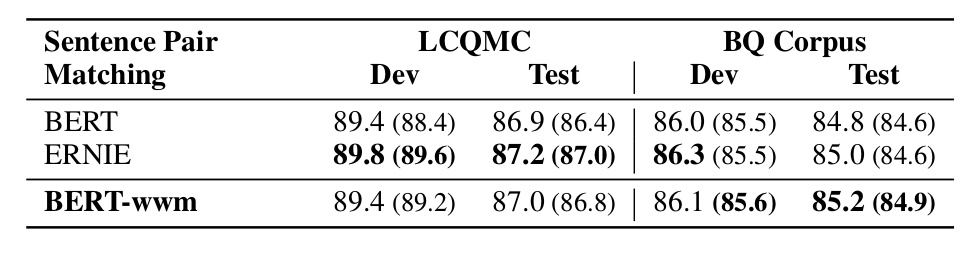
▲ 图. 句对匹配任务的实验结果
文档分类
在 THUCNews 数据集上的实验结果如下表。
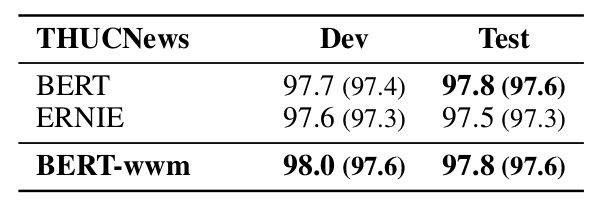
▲ 图. THUCNews数据集上的实验结果
一些技巧
下面是论文作者在实现时的一些技巧总结:
- 初始的 learning rate 是最重要的超参数,一定要好好调。
- BERT 和 BERT-wwm 的 learning rate 是相同的,但是如果使用 ERNIE,则需要调整。
- BERT 和 BERT-wwm 使用 Wiki 训练,因此在比较正式和标准的数据集上效果较好。而百度的 ERNIE 使用了网页和贴吧等数据,因此在非正式的语境中效果较好。
- 对于长文本,比如阅读理解和文档分类等任务,建议使用 BERT 和 BERT-wwm。
- 如果任务的领域和 Wiki 等差异很大,并且我们有较多未标注数据,那么建议使用领域数据进行 Pretraining。
- 对于中文(简体和繁体),建议使用 BERT-wwm(而不是 BERT)的 Pretraining 模型。
更新
7 月 30 日作者又使用了更大的数据训练了更大的模型,感兴趣的读者可以访问:
https://github.com/ymcui/Chinese-BERT-wwm
ERNIE

基本思想
ERNIE 是百度在论文 ERNIE: Enhanced Representation through Knowledge Integration提出的模型,它其实比 Whole Word Masking 更早地提出了以此为单位的 Mask 方法。
虽然它的这个名字有些大:通过知识集成的增强表示(ERNIE),但是它的思想其实和前面的 Whole Word Masking 非常类似,只是把 Masking 的整体从词多大到短语(phrase)和实体(entity)而已。
这篇论文的发表时间其实比前面的 Whole Word Masking 要早,因此我们可以认为 Whole Word Masking 可能借鉴了其思想(arXiv 上的这篇论文的时间是 2019/4/19;而 BERT 更新英文 Whole Word Masking 模型的时间是 2019/5/31)?我这里把它放到后面介绍的目的是为了能让百度的两篇论文放到一起。

▲ 图. ERNIE和BERT的对比
如上图所示,ERNIE 会把 phrase “a series of”和entity “J. K. Rowling”作为一个整体来 Mask(或者不 Mask)。
当然,这里需要用 NLP 的工具来识别 phrase 和 entity。对于英文的 phrase,可以使用 chunking 工具,而中文是百度自己的识别 phrase 的工具。entity 识别工具的细节论文里没有提及。
Pretraining的数据
训练数据包括中文 Wiki、百度百科、百度新闻和百度贴吧数据,它们的句子数分别是 21M, 51M, 47M 和 54M,因此总共 173M 个句子。
此外把繁体中文都转换成了简体中文,英文都变成了小写,模型的词典大小是 17,964。
多层级Mask的训练
ERNIE 没有使用 WordPiece,而是把词作为基本的单位。它包括 3 种层级的 Masking:基本、phrase 和 entity,如下图所示。

▲ 图. 一个句子的不同层级的Masking
训练的时候首先基于基本级别的 Masking 训练,对于英语来说,用空格分开的就是词;对于中文来说,就是字。基本级别对于英文来说和 BERT 的 Whole Word Masking 类似,但是对于中文来说就是等价于最原始的 BERT。
接着基于 phrase 级别的 Masking 进行训练,这样它可以学到短语等更高层的语义。最后使用 entity 级别的 Masking 来训练。
Dialogue Language Model
除了 Mask LM 之外,对于对话数据(贴吧),ERNIE 还训练了所谓的 Dialogue LM,如下图所示。

▲ 图. Dialogue Language Model
原始对话为 3 个句子:“How old are you?”、“8.”和“Where is your hometown?”。模型的输入是 3 个句子(而不是 BERT 里的两个),中间用 SEP 分开,而且分别用 Dialogue Embedding Q 和 R 分别表示 Query 和 Response 的 Embedding,这个 Embedding 类似于 BERT 的 Segment Embedding,但是它有 3 个句子,因此可能出现 QRQ、QRR、QQR 等组合。
实验
论文在 XNLI、LCQMC、MSRA-NER、ChnSentiCorp 和 NLPCC-DBQA 等 5 个中文 NLP 任务上做了和 BERT 的对比实验,如下表所示:

▲ 图:一个句子的不同层级的Masking Dialogue Language Model
Ablation分析
论文使用了 10% 的数据来做分析,如下表所示:

▲ 图. 不同Mask策略的Ablation分析
只用基本级别(中文的字),测试集上的结果是 76.8%,使用了 phrase 之后,能提高 0.5% 到 77.3%,再加上 entity 之后可以提高到 77.6%。
为了验证 Dialog LM 的有效性,论文对于 10% 的数据的抽取方式做了对比,包括全部抽取百科、百科(84%)+新闻(16%)和百科(71.2%)+新闻(13%)+贴吧(15.7%)的三种抽取数据方式。在 XLNI 任务上的对比结果为:

▲ 图. Dialog LM作用的Ablation分析
可以看到 Dialog LM 对于 XLNI 这类推理的任务是很有帮助的。注:我认为这个实验有一定问题,提升可能是由于数据(贴吧)带来的而不是 Dialog LM 带来的。更好的实验可能是这样:再训练一个模型,数据为百科(84%)+新闻(16%)和百科(71.2%)+新闻(13%)+贴吧(15.7%),但是这次不训练 Dialog LM,而是普通的 Mask LM,看看这个模型的结果才能说明 Dialog LM 的贡献。
完形填空对比
此外,论文还实验完形填空的任务对比了 BERT 和 ERNIE 模型。也就是把一些测试句子的实体去掉,然后让模型来预测最可能的词。下面是一些示例(不知道是不是精心挑选出来的):
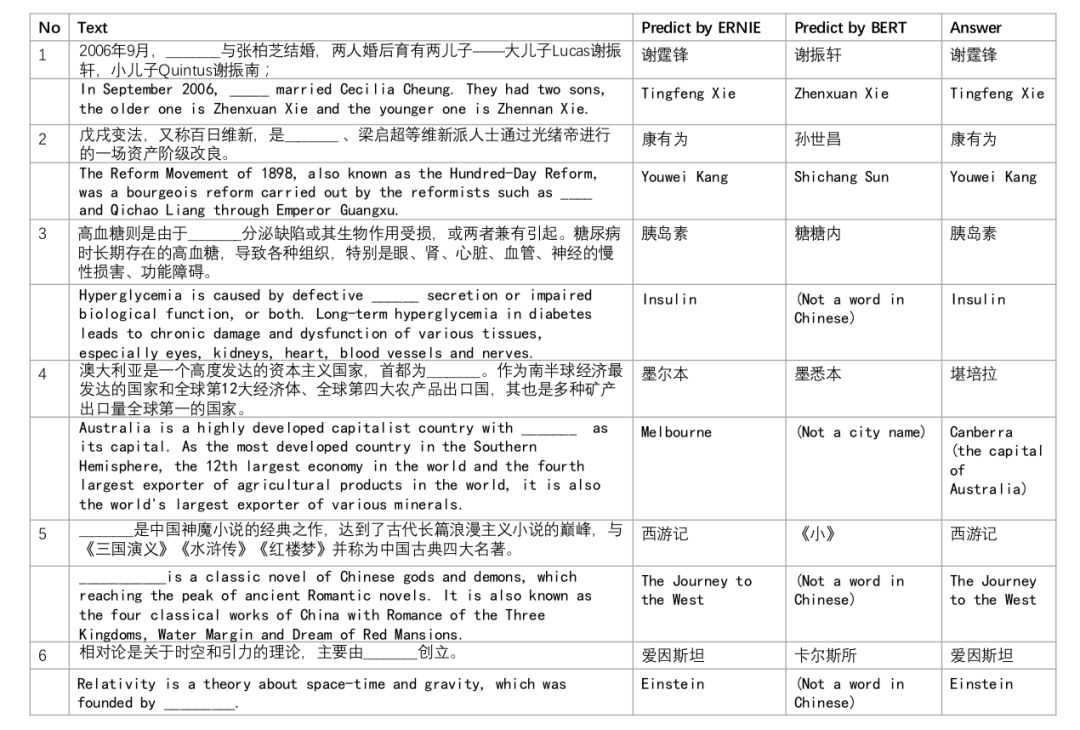
▲ 图. Dialog LM作用的Ablation分析
ERNIE 2.0

基本思想
ERNIE 2.0 的名字又改了:A Continual Pre-training framework for Language Understanding。这个名字低调务实了一些,但是和缩写 ERNIE 似乎没有太大关系。
作者认为之前的模型,比如 BERT,只是利用词的共现这个统计信息通过训练语言模型来学习上下文相关的 Word Embedding。ERNIE 2.0 希望能够利用多种无监督(弱监督)的任务来学习词法的(lexical)、句法(syntactic)和语义(semantic)的信息,而不仅仅是词的共现。
因为引入了很多新的任务,所以作为 multi-task 来一起训练是非常自然的想法。但是一下就把所有的任务同时来训练可能比较难以训练(这只是我的猜测),因此使用增量的方式会更加简单:首先训练一个 task;然后增加一个新的 Task一起来 multi-task Learning;然后再增加一个变成 3 个 task 的 multi-task Learning……
ERNIE 2.0 框架
根据前面的介绍,ERNIE 2.0 其实是一种框架(方法),具体是用 Transformer 还是 RNN 都可以,当然更加 BERT 等的经验,使用 Transformer 会更好一些。ERNIE 2.0 框架的核心就是前面的两点:构造多个无监督的任务来学习词法、句法和语义的信息;增量的方式来进行 Multi-task learning。
ERNIE 2.0 框架如下图所示:
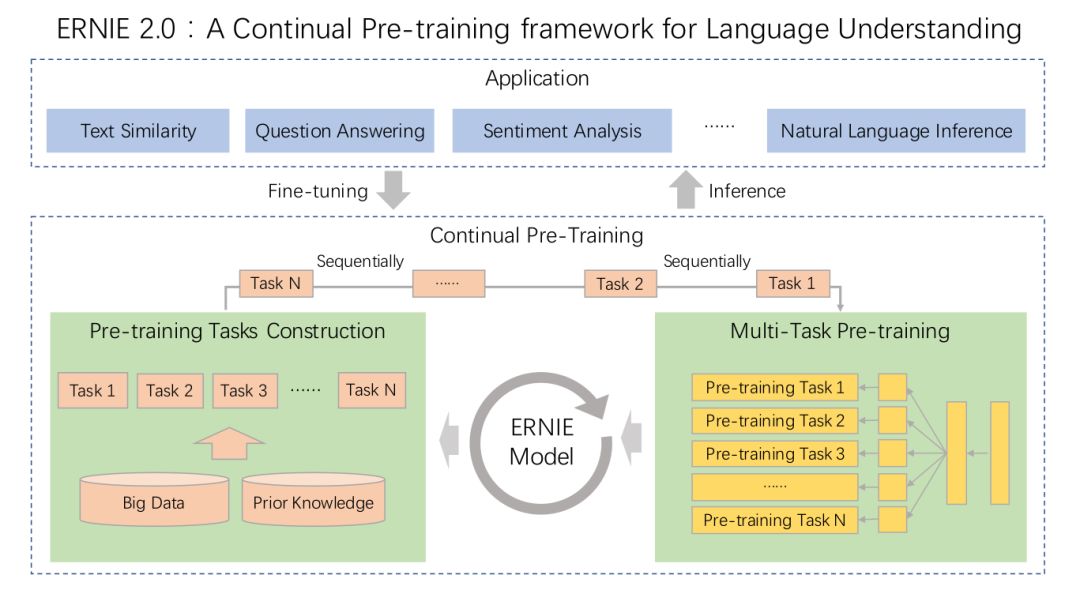
▲ 图. ERNIE 2.0框架
持续的(continual)pretraining 过程包括两个步骤。第一步我们通过大数据和先验知识来持续的构造无监督任务。第二步我们增量的通过 multi-task learning 来更新 ERNIE 模型。
对于 pre-training 任务,我们会构造不同类型的任务,包括词相关的(word-aware)、结构相关的(structure-aware)和语义相关的(semantic-aware)任务,分别来学习词法的、句法的和语义的信息。所有这些任务都只是依赖自监督的或者弱监督的信号,这些都可以在没有人工标注的条件下从大量数据获得。
对于 multi-task pre-training,ERNIE 2.0 使用增量的持续学习的方式来训练。具体来说,我们首先用一个简单的任务训练一个初始的模型,然后引入新的任务来更新模型。当增加一个新的任务时,使用之前的模型参数来初始化当前模型。
引入新的任务后,并不是只使用新的任务来训练,而是通过 multi-task learning 同时学习之前的任务和新增加的任务,这样它就既要学习新的信息同时也不能忘记老的信息。通过这种方式,ERNIE 2.0 可以持续学习并且累积这个过程中学到的所有知识,从而在新的下游任务上能够得到更好的效果。
如下图所示,持续 pre-training 时不同的 task 都使用的是完全相同的网络结构来编码上下文的文本信息,这样就可以共享学习到的知识。我们可以使用 RNN 或者深层的 Transformer 模型,这些参数在所有的 pre-training 任务是都会更新。

▲ 图:ERNIE 2.0框架的multi-task learning架构图
如上图所示,我们的框架有两种损失函数。一种是序列级别的损失,它使用 CLS 的输出来计算;而另一种是 token 级别的损失,每一个 token 都有一个期望的输出,这样就可以用模型预测的和期望的值来计算 loss。不同的 pre-training task 有它自己的损失函数,多个任务的损失函数会组合起来作为本次 multi-task pre-training 的 loss。
模型的网络结构
模型采样和 BERT 类似的 Transformer Encoder 模型。为了让模型学习到任务特定的信息,ERNIE 2.0 还引入了 Task Embedding。每个 Task 都有一个 ID,每个 Task 都编码成一个可以学习的向量,这样模型可以学习到与某个特定Task相关的信息。
网络结果如下图所示:

▲ 图:ERNIE 2.0框架的网络结构
除了 BERT 里有的 Word Embedding、Position Embedding 和 Sentence Embedding(基本等价于 Segment Embedding)。图上还有多了一个 Task Embedding。此外 Encoder 的输出会用来做多个 Task(包括 word-aware、structural-aware 和 semantic-aware)的 multi-task learning,而不是像 BERT 那样只是一个 Mask LM 和 next sentence prediction(而 XLNet 只有一个 Permuatation LM)。
Pre-training Tasks
Word-aware Tasks
1. Knowledge Masking Task:这其实就是 ERNIE 1.0 版本的任务,包括 word、phrase 和 entity 级别的 mask 得到的任务。
2. Capitalization Prediction Task:预测一个词是否首字母大小的任务。对于英文来说,首字符大小的词往往是命名实体,所以这个任务可以学习到一些 entity 的知识。
3. Token-Document Relation Task:预测当前词是否出现在其它的 Document 里,一个词如果出现在多个 Document 里,要么它是常见的词,要么它是这两个 Document 共享的主题的词。这个任务能够让它学习多个 Document 的共同主题。
Structure-aware Tasks
1. Sentence Reordering Task:给定一个段落(paragraph),首先把它随机的切分成 1 到 m 个 segment。然后把 segment 随机打散(segment 内部的词并不打散),让模型来恢复。那怎么恢复呢?这里使用了一种最简单粗暴的分类的方法,总共有
![]()
种分类。这就是一个分类任务,它可以让模型学习段落的篇章结构信息。
2. Sentence Distance Task:两个句子的”距离”的任务,对于两个句子有 3 种关系(3 分类任务):它们是前后相邻的句子;它们不相邻但是属于同一个 Document;它们属于不同的 Document。
Semantic-aware Tasks
1. Discourse Relation Task:这个任务会让模型来预测两个句子的语义或者修辞(rhetorical)关系,follow 的是 Mining discourse markers for unsupervised sentence representation learning [9]的工作,感兴趣的读者可以阅读这篇文章。
2. IR Relevance Task:这是利用搜索引擎(百度的优势)的数据,给定 Query 和搜索结果(可以认为是相关网页的摘要),可以分为 3 类:强相关、弱相关和完全不相关。
实验
论文对于英文,在 GLUE 数据集上和 BERT 以及 XLNet 做了对比;在中文数据集上和 BERT 以及 ERNIE1.0 做了对比实验。
Pretraining数据
英文数据使用了 Wiki 和 BookCorpus,这和 BERT 是一样的,此外还爬取了一些 Reddit 的数据。另外使用了 Discovery 数据集来作为篇章结构关系数据。对于中文,使用了百科、新闻、对话、搜索和篇章结构关系数据。详细情况如下表所示:

▲ 图. Pretraining数据详情
Pretraining的设置
为了和 BERT 对比,我们使用和它完全一样的设置。基本(base)模型包含 12 层,每层 12 个 self-attention head,隐单元大小是 768。对于大(large)模型包含 24 层,16 个 self-attention head,隐单元 1024。XLNet 模型的设置和 BERT 也是一样的。
ERNIE 2.0 的基本模型使用 48 块 NVIDIA 的 v100 GPU 来训练,而大模型使用 64 块 v100 GPU 训练。ERNIE 2.0 使用 PaddlePaddle 实现,这是百度开源的一个深度学习平台。
论文使用了 Adam 优化器,其中 β1=0.9,β2=0.98,batch 大小是 393216 个 token。英语的 learning rate 是 5e-5 而中文是 1.28e-4。learning rate decay 策略是 noam [10],前 4000 step 是 warmup。为了结束内存,使用的是 float16。每个 pretraining 都训练到收敛为止。
实验任务
英文实验使用的是 GLUE [11];而中文任务和前面的 Whole Word Masking 差不多,这里就不详细列举了,感兴趣的读者可以参考论文或者代码。
实验结果
英文的结果如下表所示:
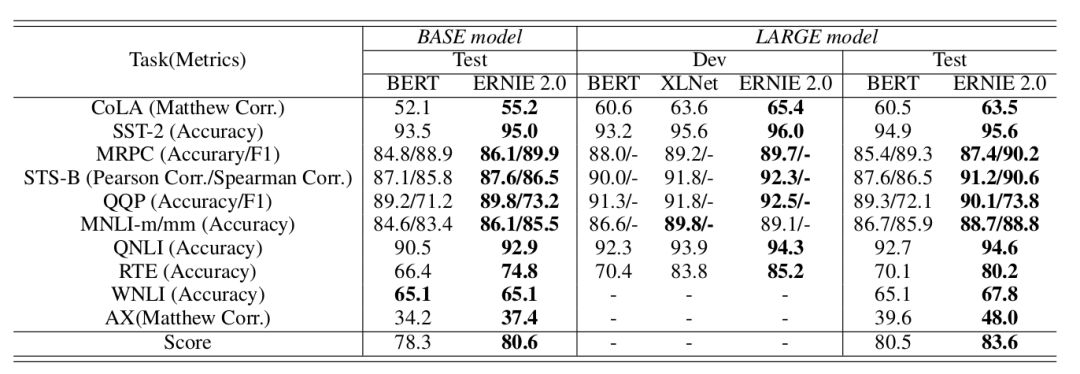
▲ 图. GLUE数据集上的实验结果
我们可以看到,不论是基本的模型还是大的模型,ERNIE 2.0 在测试集上的效果都是 SOTA 的。
中文的结果如下表所示:
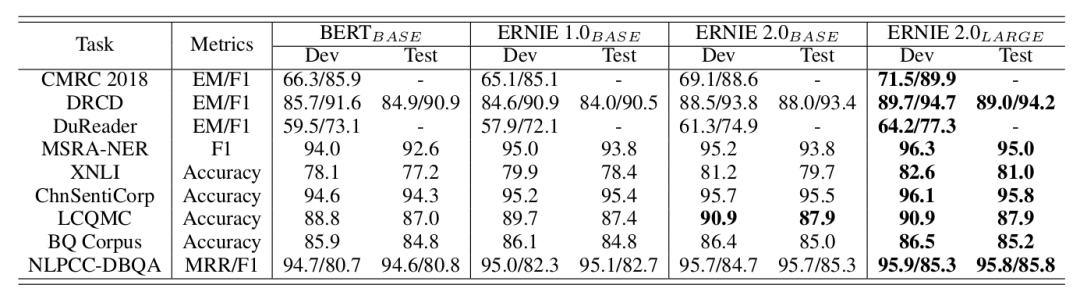
▲ 图. 中文数据集上的实验结果
代码
感兴趣的读者可以下载 Pre-training 好的 ERNIE 2.0 模型和 Fine-tuning 的代码(但是没有 Pre-training 的代码和数据):
https://github.com/PaddlePaddle/ERNIE
展望
我们可以看到进入 2019 年之后,无监督的 Contextual Word Embedding 成为 NLP 领域最热门的研究方向,没过多久就会有新的模型出来刷榜。这一方面说明了在海量的未标注的文本里包含了大量有用的语义知识,因此我们希望通过这些数据进行无监督的 pre-training。
从 ERNIE 2.0 的成功来看,通过构造更多的任务可以让模型学习更多的知识,成功的关键是怎么构造任务的监督信号(显然不能人工标注)。
另外,对于这种靠模型和训练数据的大小简单粗暴的刷榜的行为是否可持续,近期也是引起了学术界的持续关注。因为这个方向只能是有数据和计算资源的少数商业公司才有资本去这样玩,很多论文其实并没有太大的创新。
另外很多论文的结论其实可能是有矛盾的。比如最近 Facebook 的 RoBERTa: A Robustly Optimized BERT Pretraining Approach [12],它并没任何模型结构,只是改进了 pretraining 的方法就在某些数据集上比 XLNet 的效果要好,这不禁让人怀疑 XLNet 的改进到底是有 Permutation LM 带来的还是只是因为它训练的比 BERT 要好。
包括 ERNIE 1.0 提出的所谓的 Knowledge(也就是 phrase 和 entity),但是哈工大和讯飞的简单的 Whole Word Masking 模型就做的比 ERNIE 1.0 更好,这也让人怀疑 ERNIE 1.0 的改进是不是由于它的数据带来的(它是有了 wiki 之外的百度百科、新闻和贴吧等数据)。
另一方面,如果大家把注意力都集中到刷榜,而不是从更本质的角度思考 NLP 甚至 AI 的问题,只是等待硬件的进步,这也是很让人担忧的事情。在BERT的成功是否依赖于虚假相关的统计线索?一文里我也分析了学术界对于这种暴力美学的担忧,有兴趣的读者也可以阅读一下这篇文章。












