 2018-10-07 18:01:10
2018-10-07 18:01:10
聊聊用户画像的方法
我在上一篇文章《用户研究之-用好用户画像》已经讲了什么是用户画像。这篇文章讲讲用户画像的方法。
用户研究
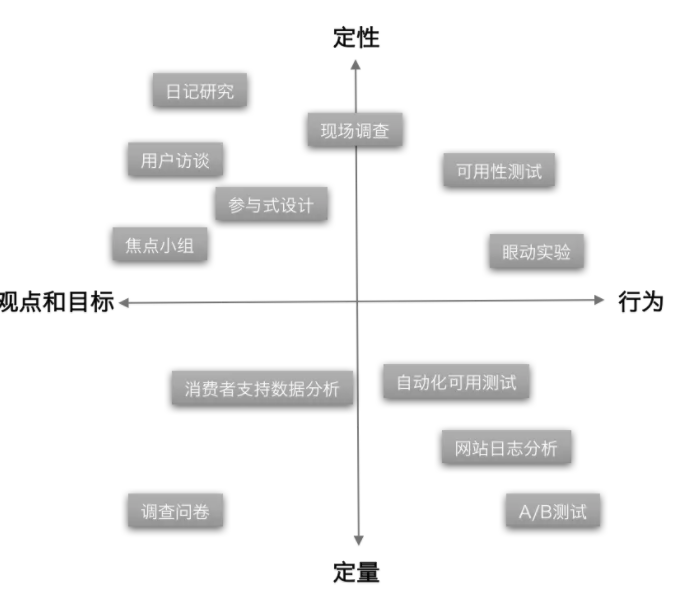
这是《赢在用户》这本书经常被人用到的一幅图,这幅图很好的归纳了用户研究的方法。根据这幅图的分类,我们来聊聊用户研究的方法。
理解用户
经常说研究用户、理解用户,那我们真正想研究的是什么内容?
听用户说什么
听用户说什么,借此来了解用户的目标和观点。目标是用户想要完成的事情,观点是用户对遇到的问题的看法。要听用户说什么,可以直接和用户进行访谈、也可以通过问卷的方式让用户回答等。
听用户说什么时,我们经常犯的一个错误是去试着说服用户接受我们的观点,特别是当用户的观点跟我们背道而驰时。记住要听用户说什么,而不要试着去说服客户接受你的观点。
听用户说什么,还应该注意“人们说的和做的可能完全不一样”的情况。
分享一个《赢在用户》这本书里面提到了一个例子。Sony在研究Boom Box概念的时候,组织了用户对Boom Box颜色进行了讨论,最终他们得出了一个结论,消费者应该更喜欢黄色的。但在会议结束后,组织者提供了黑色和黄色的Boom Box作为礼物,结果大家都选了黑色的。
合理的识别什么是用户的正确观点,什么是用户的真实观点,在听用户说什么时尤为重要。
看用户做什么
研究用户做什么,是针对用户的行为进行研究。观察用户行为的方式有很多,可以通过现场看用户做什么、也可以根据用户操作后产生的日志来分析用户的行为。
通过对用户行为的研究能发现很多问题:“用户更喜欢通过搜索框进入这个功能”、“用户喜欢在睡觉前打开软件”、“用户更喜欢阅读带图的文章”……等等。
通过研究做什么,甚至能发现用户自己都没发觉或觉得无足轻重的行为习惯。了解这些习惯,更能设计出符合用户习惯的产品。
用户研究的方法
根据用户研究的方法,可以分为定性研究和定量研究两种。
定性研究
定性研究是一种相对开放性的研究方法。定性研究是需要研究者针对少数个体,根据研究者的观察、经验、分析来进行研究在方法。定性研究并不要求统计意义上的证明,更多的是研究者本身凭借自身经验和观察对用户进行研究。
定性研究无法针对大规模的用户进行,通常只针对10到20个的典型用户。
首先,通过研究目的对用户进行分类。在研究前必须先明确我们研究的目的,再根据目的,可以选择按用户目的、行为等来对用户进行分类。
举个例子,某问答社区需要针对不同的用户进行有区别设计,选择了按用户行为来划分。有的用户喜欢写文章并和其他用户进行互动、有些用户只是上来阅读文章等。所以可以将用户分成:内容贡献者、参与者、阅读者等几个分类。
其次,在每个分类中选择若干个典型用户进行研究。在对用户分类后,为每个分类选定若干个典型用户,然后进行用户研究。
选择典型用户的方法有很多种,有特定目标的选择,也有完全随机的选择。在这里就不展开细讲了。
最后,确认是否需要新增分类或增加用户。在进行了一轮用户研究后,在通过研究的结论判断是否需要新增用户分类或者增加用户样本。
如果在研究过程中发现有用户出现明显不处于这个分类的特征,那么考虑是否增加新的分类。如果在用户身上发现了新的观点,那么可以考虑适当增加用户数量进行研究。反之,如果在一个分类用户身上已经没有新的行为或观点出现时,则可以考虑结束这个分类用户的研究了。
定性研究方法
一对一访谈
一对一访谈是采用与用户进行一对一的谈话的方式,通过跟用户面对面的交流来认识和了解用户的一种方式。
一般一次只选择一个用户进行访谈,一是因为这样容易听清用户的观点,同时也避免了多个用户之间观点相互影响。但是,在有条件的情况下,鼓励多个研究者针对一个用户进行访谈,这样能从多个不同的角度了解用户。
这里列举几个用户访谈过程中会遇到的一些问题:
照本宣科的提问。事实上在访谈过程中,经常会听到用户提出了我们毫无准备的问题,要善于从这些问题中挖掘出新的问题。可以提前准备问题,但切记不要照本宣科。
用户讲别人的观点。“我认为他们可能会……”,这个是用户经常出现的表达方式。当用户提起他人的观点时,我们要适当的引导“那你遇到这种情况时会怎么做?”
试图说服用户。适当引导用户,但不要试着说服用户接受我们的观点。当我们认为用户说错了,也不要试着去强硬地去纠正。要去理解用户为什么犯错误了。更何况当我们认为用户错的时候,很有可能错的是我们。
访谈离题太远。要让用户说出他自己的故事,但是要避免离题太远。用户经常会发散地讲述他们的故事,从产品使用,到日常生活,再到街头八卦。我们虽然允许用户小范围离题,但要注意引导用户。
现场调查
现场调查就是到真实的现场去看用户怎么使用产品。
现场调查经常可以看到一些场景和习惯是用户觉得没必要说的,甚至我们觉得没必要问的问题。
现场调查也有一些注意事项:
做现场调查,应该尽量让用户从事他日常处理的事情,除非有必要,尽量避免构造一个场景让用户去执行。
在用户操作过程中,调查人员要尽量避免干扰用户。碰到有疑问的可以先记下来,等用户执行完成后再进行询问。
用户在被询问或观察的情况下,很有可能为了迎合调研者而刻意改变日常行为。
在用户演示完成后,我们还应该针对一些问题和用户进行交谈。这部分内容有点类似于用户访谈的形式,但是内容变成了针对于用户行为的访谈。
可用性测试
可用性测试类似于现场调查。调研者通过设置目标让用户完成,观察用户在完成目标过程中遇到的障碍或困难,以此发现我们产品设计过程中存在的问题。
在这个过程中也可以收集到用户在使用过程中的建议。
焦点小组
焦点小组是一种调研者和用户通过做座谈的方式进行的一种用户意见收集的形式。调研者作为座谈会的主持人,引导用户表达出他们的观点。
作为主持人控制场面和话题很重要,避免用户和用户之间太广泛的讨论。
定性研究小结
定性研究实行的难度比较小,在某种程度来讲,定性研究是可以随时随地的进行的。而且在定性研究过程中,我们往往面对的是真实的用户,更容易让我们理解和梳理出用户的故事。
定性研究不需要特别专业的计算机知识,但是对调研者自身的分析和总结能力要求比较高。也应该看到,调研者自身的态度很容易影响到调研结果。要避免过于主观的去分析用户的行为和观点。
定性研究的方法也有其缺点,定性研究一般研究对象在10到20个之间,样本数量较小,所以个体差异对整个调查数据的影响较大。所以,定性研究缺乏数据的支撑。定性研究无法自证我们的调研结论的全面性。
但是特定情况下定性研究却是可以发挥很大作用的。比如,在调研资源不足时,在我们没有量化的数据时,在某些要求不太严格的小项目启动时,都可以考虑采用投入成本不高的定性研究。
定量研究
定量研究是基于一定的用户数据进行研究的方法。定量研究需要基于用户的行为或观点产生的数据,通过数学统计的方法来获得研究结果。
定量研究步骤
定量研究面对的是成千上万甚至于海量的用户数据。所以,定量研究需要借助于数学的统计和计算机算法来完成。虽然近年来人工智能在用户研究领域已经取得了较大的发展,但是用户研究还是得从人为的假设开始。
来看一下如何开展定量研究:
首先,根据我们的调研目的,对用户分类并进行假设。
先根据调研的目的对用户进行初步的分类。这一步跟定性研究类似,通常的做法是在定量研究开始前先进行一次定性研究,通过定性研究的结论来作为定量研究的分类假设。
其次,基于对用户分类的假设,对数据进行计算和分类。
根据我们既定的假设和已有的用户数据,利用数学的方法进行统计和分类。这一步需要借助于数学和计算机的算法,所以这个步骤经常是需要工程师来完成。
最后,分析分类结果,并适当调整用户分类。
计算机分类出来的结果还需要进一步分析,分析一下计算出来的结果是否符合预期。这个步骤可以验证我们对用户分类的假设。
数学的统计可以避免人为主观的影响,有时候甚至能发现一些意想不到的问题结论。你可以知道“原来还有每个月成千上万购物的用户”,“原来那么多用户在挤地铁时使用产品 ”……
但是也要警惕一点:数据也是会骗人。例如数据显示“某功能男人比女人多一倍的打开概率”,当你知道女人打开概率是1%时,这个结论多么可笑。再次提醒:数据是死的,关键还得看你怎么解读数据。
定量研究的方法
问卷调查
问卷调查是指通过给用户发问卷的方式来进行用户研究。
问卷调查远没有看起来那么简单。合理的设计问卷,不同的问卷设计方式在同一个问题上可能会得出完全不同的结果。
举个例子,问一个用户“当有奖品时您是否会分享”,也可以问“您在下列情况下,哪些情况您会分享?”,还可以问“您曾经转发到朋友圈的文章有一下哪几类?”,同一个问题不同的提问方式你可能会得到一些不一样的结论。
如果对问卷调查不清楚,或者对用户不了解,建议用迭代的方式来进行问卷调查。先针对小部分用户进行测试,然后调整问卷,再进行下一轮的问卷调查。
不可否认,问卷调查也是研究用户“说什么”的一种方式,不可避免的部分用户可能会口是心非的回答问题。要适当的考虑这部分用户对调研结果的影响。
日志和用户数据分析
日志和用户数据分析是在产品已经上线的项目里面使用的方法。用户在使用产品过程中会留下很多用户数据或日志,我们以此为分析对象。
相比于其他的用户调研的方法,日志和用户数据分析是用户在真实的场景下使用产品过程中留下的数据,是最全面也是最真实的反应用户行为的一种方式。但是日志和用户数据分析研究的是用户的行为,并不能反映用户的观点。日志和用户数据分析可以和问卷调查或定性研究结合使用,将用户行为和用户的观点结合起来分析。
定量研究小结
定量研究是针对一定数据量的用户观点或行为进行分析的方法,所以可以在数学上证明用户分类的正确性。同时,定量研究经常可以利用计算机进行计算,这意味着我们可以针对更多的用户数据进行分析。
定量研究对技术的要求比较高,需要计算机工程师一起参与分析。因为定量研究是通过数学的方式进行统计的,所以其得出来的分类结论看起来会更加离散和复杂。这无疑提高了后期进行用户画像的难度。
进行用户画像
到这里我们对用户已经有了一个大概的认识,从这里我们要开始利用我们收集到的用户信息进行用户画像了。
细分用户
用户分类可以让我们更加理解和聚焦某个分类用户的需求,更细的分类有助于我们更精细化地去运营数据。但这也不代表用户分类越多越好,太多的用户分类会让团队在使用用户画像的过程中陷入困境。试想一下,如果一个产品存在20~30个用户画像,记不记得住都是一个问题,还怎么在平时工作中使用。
那么多少个用户分类合适?《赢在用户》这本书建议的是3~6个。6个以内的用户让团队容易记忆,并且更容易使用。
针对某些比较大型的产品,6个用户分类可能无法满足需求。这个时候可以考虑针对某个大功能进行用户画像。例如,某个综合性社区既有论坛功能又有电商功能,那么可以考虑针对论坛模块和电商模块分别进行独立的用户画像。
进行用户分类
根据分析目的的不同和产品的不同阶段,可以采用不同的分类方式。
按用户目标划分
按用户目标划分是一种常见直接的方法,因为一个用户使用我们的产品总是带着一种目的而来。例如针对一个旅游社区产品,用户可能是想了解目的地、也可能是想了解当地攻略、还有可能是想寻找一起去旅游的同行者等。

我们还可以更深入的了解用户目标的动机,对动机进行划分。例如,在用户进入社区后,用户最终的目标是不一致。

在我们规划产品功能和产品结构框架的时候,按用户目的划分是一种非常有用的方法。通过这种方法设计出来的产品用户理解起来更直接。
按用户行为划分
用户使用产品会出现不同的行为。例如对一款音乐产品来说,用户可能会出现不一样的行为,有些用户直接搜索喜欢的音乐、有些通过其他用户推荐来播放、有些用户在听完之后会分享给其他用户等。
当我们的产品的功能比较垂直单一时,用户的行为比用户的目标更能区分用户之间的差异,这时候按用户行为划分是一个很好的办法。例如对于音乐产品,用户的目标比较聚焦在听音乐这件事上,这时候如果按用户目标来划分的话,用户的差异可能没那么大。利用用户使用产品的行为来划分,会是一个很好的分类方式。
按用户所处阶段划分
用户使用产品是一个渐进的过程,每个用户都会经历新手期、发展期、专家期等阶段。每个阶段用户都会遇到不同的问题,新手期用户面临熟悉产品的问题、发展期面临成长的问题、专家期面临新鲜度流失的问题等。
在产品启动后运营阶段,按用户所处阶段划分,能更好发现用户在各个阶段遇到的问题。
交叉划分
按一维特征对用户进行划分是比较直接的,但是我们面对的用户往往是多样的。用户更多是在两三个维度呈现出不一样的特征,所以可以利用交叉的方式来进行用户划分。
例如还是针对一个旅游社区来分析。我们将用户的目标分成两类,一类是想深入了解目的地的用户,一类只是去目的地走走的用户。除此之外,我们的用户还分成新用户和老用户。来看看怎么使用用户的目标和用户所处的阶段来进行划分。

除了二维的划分法,我们还可以将用户的行为加入进去。例如,根据用户的行为,我们将用户分成内容生产者和消费者。那么我们的分类就变成了下图所示。
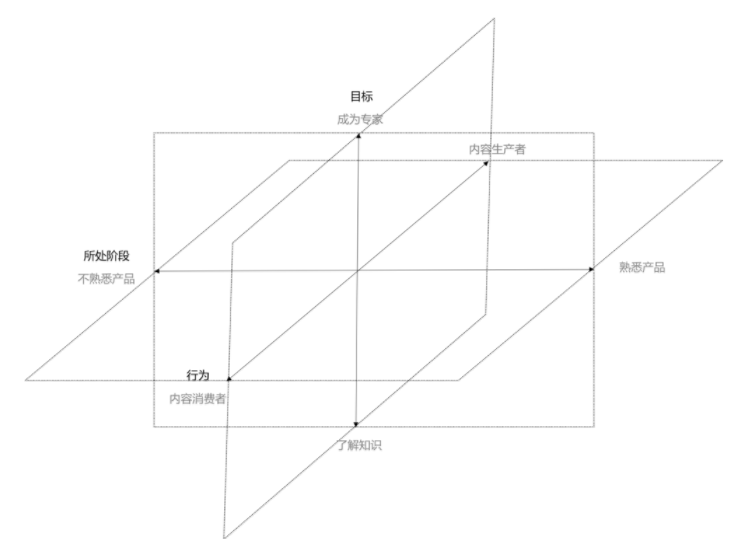
还需注意,划分了用户分类后,不代表这个分类区间内一定有用户。例如,一个用户只想了解知识的新手用户是不会成为内容生产者的。那么这个分类区间是可以删除的。
定量细分
在我们做用户的定量研究时,我们可能会得到大量的用户数据。针对大量的数据再使用人工定性的细分方式就处理不过来了,这时候就要选择定量细分的方式了。
处理大量的用户数据,可以用定量细分的方法来进行。
首先,确定用户关键属性。
在大量的用户数据里面,找到我们需要计算的用户属性。例如性别、所在地、职业、年龄等等。
虽然我们能收集到用户海量的数据,但并不是所有用户属性都是必须的。我们选择属性必须是对产品用户分类产生重大影响的属性。例如,用户的性别不同会出现完全不同的阅读习惯。这时候性别这个属性就是关键的属性。
其次,将用户数据抽象成数学模型。
我们拿到的属性通常并不一定是一个数值,我们需要将数值进行数学模型的抽象。例如:性别分“男”、“女”,可以用数字“1”、“-1”来表示。
最后,利用计算机算法进行分类。
计算机的发展,特别是近几年人工智能飞速发展,当前已经有了很多比较成熟分类的算法,在这里就不展开说明了。有兴趣的可以翻阅一下相关资料。
举一个例子,某一个阅读产品对于用户进行细分。选取了性别和阅读财经新闻次数两个属性来进行分类。从下图可以看到,用户分部聚集在两个区域。这两个区域可以大概的看成是两个用户的分类:
男,喜欢阅读财经新闻。
女,不太关注财经新闻。
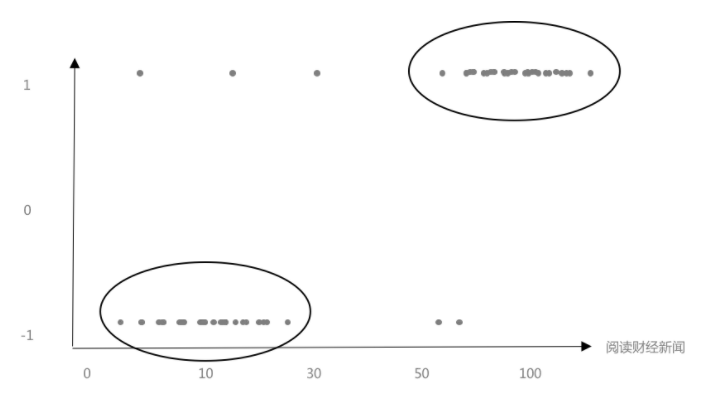
同理,我们还可以选取更多的属性来进行分类计算。当前很多新闻阅读产品,在做用户分类的时候,已经考虑到了上百个属性,从性别、年龄、到所在城市等。随着属性的增加,越能形象的描述一个用户。
验证用户分类
用户分类确定了之后,怎么判断我们分类是正确的?《赢在用户》这本书给了几个确认方法:
是否能解释关键差异
什么是关键差异?就是一个用户能区别于另一个用户的差异。而用户的分类需要能解释这些关键差异。
例如,我们识别出用户的访问频率是关键的差异,有些是经常访问的、有些用户是偶尔访问的。用户的分类应该是能明显的区分出经常访问的和偶尔范围的用户。
是否足够不同
不同的分类用户必须有足够的不同。例如,一个用户的关键行为和观点都是一致的,只有年龄是不一致的,这时候是不能将着其分成两类用户的。
是否像真实的人
用户应该是一类用户的代表,所以我们分类出来的用户也应该是一个真实的人的代表。
通俗来讲,就是我们抽象出来的用户,要具备应该真实人物应该具备的特征。而不应该是个相互矛盾的人。例如,不修边幅的完美主义者,一个出手阔绰的实用主义者。
让一个分类用户看起来像一个真实的人,有助于让使用者引起共鸣。
是否能够描述群体
分类用户应该是一类用户的代表。所以,当我们提带这个分类用户时,需要能够描述这个群体。提到这个用户就能想到其所代表的群体。这也是我们后期能使用这个角色的基础之一。
是否覆盖了主要用户
在完成了所有用户分类后,我们所有的用户应该是能被归类成某一个分类用户的。如果存在某一些无法归类的用户,可能就要尝试其他的用户分类方式或者增加一个新的分类了。
是否能影响决策
能够在我们后期决策时使用到这些用户分类,才能体现我们用户分类的价值。例如,我们针对不同的用户的目标进行模块的划分,针对不同用户的付费情况进行针对性的运营。
上一篇:用户研究之-用好用户画像
下一篇:用户研究之-进行用户画像












