 2021-11-08 14:53:15
2021-11-08 14:53:15
前言
作为一个合格程序员必备的基本技能之一,正则表达式是不言而喻的。但是为什么掌握起来这么难,甚至觉得用起来很难呢?本文将向您展示如何一次性使用Python正则表达式。
1.正则表达式的组成
在介绍如何使用Python的正则表达式时,我们需要知道正则表达式的各种功能以及它们是如何组成的。
正则表达式可以从非结构化文本中提取我们想要的内容,其本质是模式匹配,也是智能的初始手段。现在它已经广泛应用于自动化信息处理的过程中,从爬虫到人工智能,无处不在,而且它的需求量相当大。
说到写正则表达式,N中很多博客都提到了一个我之前用过的神奇网站http://www.txt2re.com/,如果你不懂正则表达式,又想偷懒自动生成,只需要在这个网站复制粘贴一个最复杂的情况,然后在视觉上点击组合你想要匹配的内容,自动生成你想要的正则表达式。
但是很遗憾,这个网站目前无法开通。这也告诉我们,核心技术掌握在自己手里是真的。现在我们来看看如何写正则表达式。下面是正则表达式使用。不同的语言有不同的实现方法。今天,我们主要关注三种正则表达式的匹配方法,使用python来获得我们想要的目标片段。对于其他方法,我们将在后面解释。
首先确定输入的一般格式。
在此输入的一般格式中找到您需要和不需要的内容。
通过正则表达式匹配。
提取临时结果,并将它们保存在我们需要的数据结构中。
2.使用python表示正则表达式过程。
如果我们使用python来正则化正则表达式,我们主要会经历几个步骤:
导入包
根据需要指定正则表达式。
编译自定义表达式。
根据其表情进行搭配。
输出结果
1、3、5都是比较容易的部分,最难的部分主要包括两个步骤,一是制定一个符合要求的正则表达式,二是如何匹配。最后,我们将简要介绍输出结果。
3.写正则表达式
写正则表达式是它的核心。如何写出符合我们想法的正确表达?这里我们介绍以下两个要构建的部分:
一个完整的词。
这一部分不是我们需要的,只是一些留在我们需要的中间的部分。照原样复制原文,不要添加多余的表格。
要匹配的零件
这部分让我们想要提取内容,而我们想要匹配的部分是通过正则表达式表达成两部分,一部分是我们匹配的字符,例如:
匹配字母数字和下划线
w匹配非字母数字和下划线
s匹配任何空白字符,相当于[tnrf]。
匹配任何非空字符。
d匹配任何数字,相当于[0-9]。
匹配任何非数字的数字
匹配字符串开始
z匹配字符串的结尾。如果有换行符,则只匹配换行符之前的结束字符串。
z匹配字符串的结尾
g匹配上一次匹配完成的位置。
b匹配单词边界,即单词和空格之间的位置。例如,“erb”可以与“never”中的“er”匹配,但不能与“verb”中的“er”匹配。
b匹配非单词边界。“erb”可以和“动词”中的“er”搭配,但不能和“never”中的“er”搭配。
n、t等。匹配换行符。匹配标签。等待
一.9匹配第n个数据包的内容。
10匹配第n个数据包的内容,如果匹配的话。否则,指八进制字符代码的表达。
另一个是匹配模式,它决定了我们如何匹配:
匹配字符串的开头
$匹配字符串的结尾。匹配除换行符以外的任何字符。指定了DOTALL标志,包括换行符在内的任何字符都可以匹配。
[…]用于表示一组单独列出的字符:【amk】匹配“a”、“m”或“k”
[……]不在[]中的字符:[a,B,c]匹配除A,B和c以外的字符
Re*匹配0个或更多表达式。
Re匹配一个或多个表达式。
re?匹配前一个正则表达式定义的0或1个片段,非贪婪方式。
Re{ n}与前n个表达式完全匹配。例如,o{2}不能匹配“Bob”中的“o”,但可以匹配“food”中的两个o。
Re{ n,}匹配n个以前的表达式。例如,o{2,}不能匹配“Bob”中的“O”,但它可以匹配“foooood”中的所有O“O { 1,}”相当于“O”。o{0,}”相当于“o*”。
Re{ n,m}匹配由前面的正则表达式定义的段n到m次,贪婪的方式。
A| b匹配a或b
(重新)将正则表达式分组,记住匹配的文本。
(?Imx)正则表达式包含三个可选标志:I、m或x。只有括号中的区域会受到影响。
(?-imx)正则表达式关闭I、m或x可选标志。只有括号中的区域受到影响。
(? re)类似于(…),但不代表一个组。
(?Imx:)在括号中重新使用I、m或X可选标志。
(?-imx: re)不要在括号中使用I、m或X可选标志。
(?#……)注释
. (?= re) 前向肯定界定符。如果所含正则表达式,以 … 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 (?! re) 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 (?> re) 匹配的独立模式,省去回溯。两者搭配即可完成我们想要的结果,虽然这里列举了很多,但是我们常用的就那几个,正则表达式的简单划分将正则表达式划分为元字符、反义、量词和懒惰限定词。我会在后面的部分给出一个实例。当我们的正则表达式撰写完毕后,我们使用下面的函数获得我们的匹配模板。
re.compile(pattern[, flags])4. 匹配的方式
正则表达式匹配的方式主要有3种match, search和findall。如果你懂英语的话,就知道它们的区别,这里前两个都是单一匹配,只会匹配一个流程,如果有多个符合匹配规则的,它们只会返回第一个结果,而findall会把所有符合候选的都匹配出来。而前两个的区别就是match必须是开头就要能够匹配,也就是和startwith差不多的效果,而search则可以在任意位置进行匹配。
下面看一下三个方法的参数表示,其中pattern为我们制定的正则表达式,string为我们要匹配的字符串,flags表示匹配模式:
re.match(pattern, string, flags=0)
re.search(pattern, string, flags=0)
findall(string[, pos[, endpos]])因此我们选择方式时有以下几个步骤:
是否需要匹配多个?是,选择findall
是否需要从头匹配?是,选择match
一般情况使用search
5. 匹配结果展示
匹配结果展示主要有以下四个部分组成:
group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
span([group]) 方法返回 (start(group), end(group))。例如下面这个例子,主要表现了我们如何调用这四个部分。
>>>import re
>>> pattern = re.compile(r'd+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print m # 返回一个 Match 对象
<_sre.SRE_Match object at 0x10a42aac0>
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)6. 举一个简单的例子
一个更好的,更直观易懂的方法是如下这个例子,相比较刚才使用数字索引,它将每一个匹配内容语义化,使得代码更加容易理解。
contactInfo = ' ( Nucleus (span 2 3) (rel2par span)'
pattern=re.compile(r'(?P<nuclearity>w+) (span (?P<start>w+) (?P<end>w+)) (rel2par (?P<relation>w+))')
match = pattern.search(contactInfo)
print(match.group()) # Nucleus (span 2 3) (rel2par span)
print(match.group("nuclearity")) # Nucleus
print(match.group("start")) # 2
print(match.group("end")) # 3
print(match.group("relation")) # span从上述的例子中我们就可以获得最直观的结果,我们只需要将这些结果存入到我们需要的数据结构中即可。
7. 其他一些补充知识
7.1 匹配常用的一些格式
如果我们只需要匹配一些常用的格式,如姓名、身份证、邮箱、电话号码等,都是有现成的工具直接生成,不需要我们进行再次编写。
7.2 匹配中文字符
如果你只是想匹配若干个中文汉字,使用下面的正则表达式:
[u4E00-u9FA5s]+ 多个汉字,包括空格
[u4E00-u9FA5]+ 多个汉字,不包括空格
[u4E00-u9FA5] 一个汉字这里还有匹配更全的中文字的方法。
提到用正则表达式匹配汉字,很容易搜到这个[u4e00-u9fa5],但是它不算全面,不包含一些生僻汉字。
本文对此问题做一个梳理。
以下是比较全面的汉字Unicode分布,参考Unicode 10.0标准(2017年6月发布):
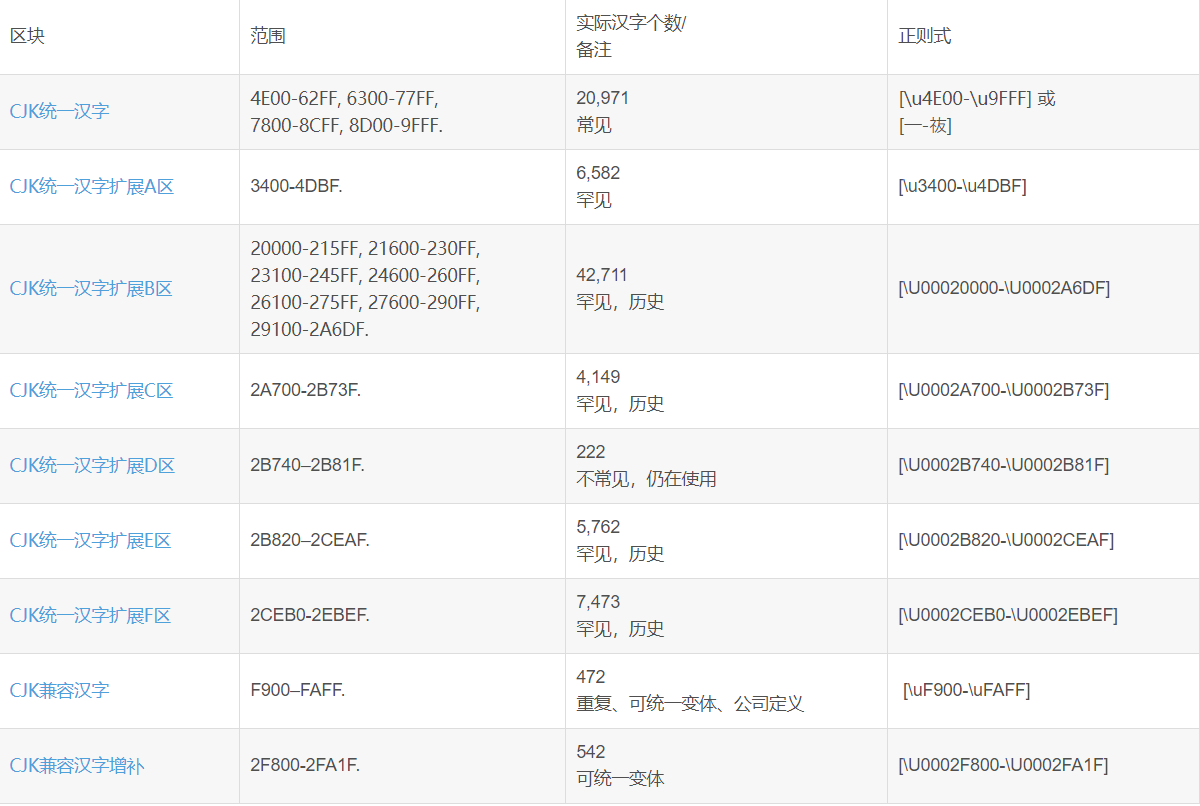
如果想表示最普遍的汉字,用:
[u4E00-u9FFF] 或 [一-?]
共有20950个汉字,包括了常用简体字和繁体字,镕等字。
基本就是GBK的所有(21003个)汉字。也包括了BIG5的所有(13053个)繁体汉字。
一般情况下这个就够用了。
说明:
仅仅未包括出现在GBK里的CJK兼容汉字的21个汉字:郎凉秊裏隣兀嗀﨎﨏﨑﨓﨔礼﨟蘒﨡﨣﨤﨧﨨﨩
CJK兼容汉字用于转码处理,日常中是用不到的,所以不包括也没什么问题。
注意此凉非彼凉,兀也不是常用的那个,虽然用眼睛看是一样的,参见
http://www.zhihu.com/question/20697984
如果想表示BMP之内的汉字,也就是Unicode值<=0xFFFF之内的所有汉字,用:
[u4E00-u9FFFu3400-u4DBFuF900-uFAFF]
这个包含但不限于GBK定义的汉字,共有28025个汉字。
说明:
和上面相比,主要是多了CJK统一汉字扩展A区,这是1999年收录到Unicode 3.0标准里的6,582个汉字。
CJK统一汉字扩展A区,包括了东亚各地区(陆港台日韩新越)的汉字,有很多康熙字典的繁体字。
如果想尽可能表示所有的汉字,用:
[u4E00-u9FFFu3400-u4DBFuF900-uFAFFU00020000-U0002EBEF]
这个包含上表的所有88342个汉字
说明:
1, 以上正则表达式不会匹配(英文、汉字的)标点符号,不会匹配韩国拼音字、日本假名。
2, 会匹配一些日本、韩国独有的汉字。
3, 包含了一些没有汉字的空位置,这通常不碍事。
4, u及U的正则语法在Python 3.5上测试通过。
有些正则表达式引擎不认uFFFF和UFFFFFFFF这样的语法,可以换成x{FFFF}试一下;有些不支持BMP之外的范围,这就没办法处理CJK统一汉字扩展B~E区了,如notepad++。
7.3 匹配一些特殊符号
正则表达式的各种括号的用处以及如何进行括号的匹配。
匹配小括号中的内容
import re
string = 'shain(love)fufu)'
p1 = re.compile(r'[(](.*?)[)]', re.S) #最小匹配
p2 = re.compile(r'[(](.*)[)]', re.S) #贪婪匹配
print(re.findall(p1, string))
print(re.findall(p2, string))
输出:
[‘love’]
[‘love)fufu’]
匹配中括号中的内容
import re
string = 'shain[胖妮shain和傻夫夫fufu]fufu)'
p =r'[[][Ww]+[]]'
print(re.findall(p, string))
输出:
[’[胖妮shain和傻夫夫fufu]’]
匹配大括号中的内容
import re
string = "shain,fsf{傻夫夫,grr},胖妮{fsf,1201}"
p = re.findall(r'({.*?})', string)
print(p)输出:
[’{傻夫夫,grr}’, ‘{fsf,1201}’]












