 2021-11-08 21:52:18
2021-11-08 21:52:18
在分布式系统中,通常需要唯一地识别大量的数据、消息、http请求等。如链接traceId、Id号、订单序列号、操作记录序列号、优惠券id等等。
此时数据库自增主键已经不能满足需求,需要一个能够生成分布式ID的系统。
分布式ID的特性
全球唯一。ID不能重复,这是最基本的要求。
增量。增量有利于关系数据库的索引性能。除了常见的连续增量,如1001、1002、1003等。分布式ID也有递增趋势的形式,即下一个ID保证比上一个ID大但不连续。这个好处可以防止关键信息的泄露,比如toc业务中暴露给用户的ID,可能会暴露用户数量。(订单编号相同)
高可用性。为多个服务提供ID服务,一旦出问题会产生严重影响。
出入方便。遵循即用的设计原则,访问文档应该尽可能简单。
高性能:在压力测试下必须表现良好,如果达不到要求,会导致高并发环境下的系统瘫痪。
灵活性:每个业务场景对ID都有不同的要求,ID的生成要灵活、可配置,尽可能满足需求。
解决方案
1. UUID
UUID是通用唯一标识符的缩写,它包含32个十六进制数字,由连字符分成五段。形式为8-4-4-4-12字符串,包含36个字符,例如:
321 DSA 13-das2-d231-gfdd-213 as8as d 899
UUID是由某种算法机器产生的。为了确保UUID的唯一性,规范定义了包括网卡的MAC地址、时间戳、名称空间、随机或伪随机数、时间序列以及根据这些元素生成UUID的算法在内的元素。
优点:
性能非常高,本地生成,无网络消耗。
生成简单,无高可用性风险。
有利于信息安全,因为可读性差且不规则。
缺点:
太长,不易存放。
无序对MySQL索引不利。在InnoDB中,UUID的无序可能导致数据位置频繁变化,严重影响性能。
UUID无法识别商业含义,可读性差。
2. 数据库自增 ID
利用数据库自增ID的特性,比如MySQL的auto_increment。它的优点是数字化,可以自动增加。当然,缺点是并发场景中的性能瓶颈。
优点:
简单,使用数据库自己的功能。
严格的ID连续自增可以实现一些对ID有特殊要求的服务。
缺点:
存在重复发布的风险,比如MySQL数据库的主从切换场景。
信令性能受限于数据库性能。
对数据库的依赖性强,当数据库出现异常时,整个系统不可用。
进一步优化:
放弃主从复制的高可用性架构,采用多主架构。每个主库设置不同的起始值和相同的步长,保证了数字段的隔离。
3. Redis
Redis中的incr命令可以实现原子自增量。与数据库相比,Redis可以支持非常高的并发性和良好的性能。
但是,需要考虑以下两种情况导致的数据不一致:
停机后重启恢复,但未及时初始化。
主从切换,主从数据同步延迟。
优点:
简单能干。
高并发环境下性能好,优于数据库。
缺点:
可能会重复。
有必要确保Redis服务的高可用性。
4. Zookeeper 实现
使用Zookeeper作为分段节点的协调工具,每个服务器首先从ZooKeeper获取一个数字,比如ID为[1,1000]。此时最大值1000保存在Zookeeper上,每次获取都会进行判断。如果ID ID=1000,则更新本地当前值;如果是1001,Zookeeper上的最大值会更新为2000,本地缓存段也会更新。(相当于用Zookeeper实现了基于数据库的分段模式)
优点:
效率高。
缺点:
维护成本高,不能同时满足多个系统对ID的需求,不够灵活。
5、基于数据库的号段模式
段模式的思想是客户端从数据库中取出一批ID供程序每次使用,从表中获取本次的ID值范围,如[1,1000],然后将应用的段[1,1000]加载到内存中。表格参考如下:
CREATE TABLE id_generator(
整数(10)不为空,
Max_id bigint(20) NOT NULL COMMENT '当前最大id ',
step int(20) NOT NULL COMMENT '号段的布长', biz_type int(20) NOT NULL COMMENT '业务类型', version int(20) NOT NULL COMMENT '乐观锁版本号', PRIMARY KEY (`id`) )等这批号段ID用完,再次向数据库申请新号段,对max_id字段做一次update操作(update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX),update成功则说明新号段获取成功,新的号段范围是(max_id ,max_id +step]
进一步优化:
在号段消耗一半的时候,提前预留下一段号段。将预留号段时机提前,减少阻塞发生概率。一般称此为双Buffer机制。不同业务可以设置不同的生成规则。
5.雪花算法
雪花算法(Snowflake)是twitter公司内部分布式项目采用的ID生成算法,开源后广受国内大厂的好评,在该算法影响下各大公司相继开发出各具特色的分布式生成器。
雪花算法,不依赖其它系统或数据库,以服务的方式部署,供其它服务调用,稳定性高,生成 ID 的性能也非常高。
给每台机器分配一个唯一标识,然后通过下面的结构实现全局唯一ID:
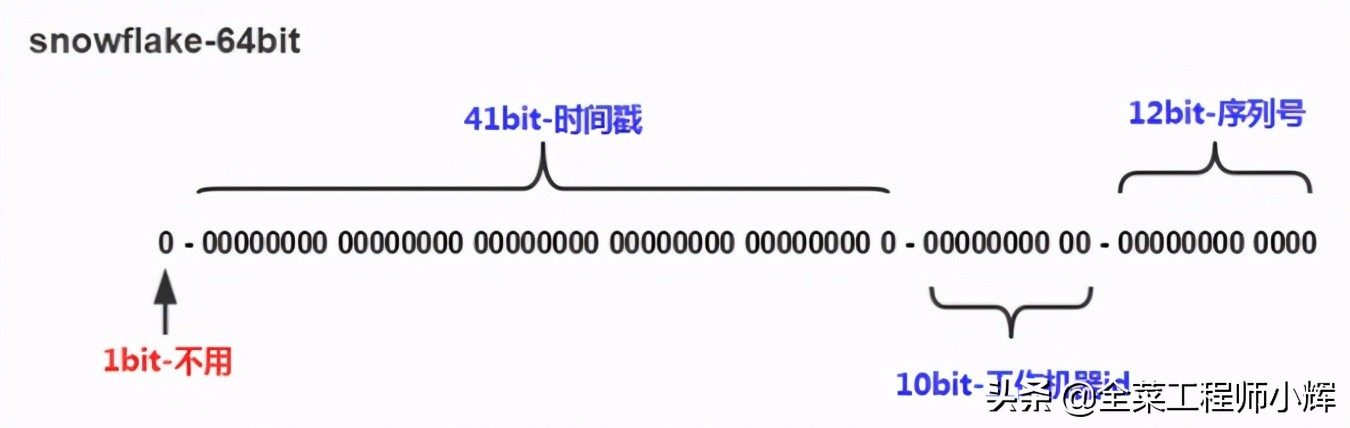
- 1位。未使用(二进制中最高位为1的都是负数,所以这个最高位固定是0)
- 41位。毫秒级时间(41 位的长度可以使用 69 年)
- 10位。包含5位datacenterId和5位workerId(10位的长度最多支持部署1024个节点)
- 12位。最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)
由于在Java中64bit的整数是long类型,所以在Java中SnowFlake算法生成的id就是long来存储的。
优点:
- 生成性能高。
- 整体上按照时间自增排序。
缺点:
- 强依赖机器时钟,如果时钟回拨,可能会导致服务异常。
- 不能同时满足多个系统对ID的需求,不够灵活。
- 在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,会出现不是全局递增的情况。
6.Tinyid
Tinyid是滴滴开源的分布式ID生成方案,开源地址见于参考文档1,只提供基于号段模式来生成ID(加入了双Buffer机制)。
7.Uidgenerator
UidGenerator是由百度技术部开发,开源地址见于参考文档2,基于Snowflake实现的优化算法。借用未来时间和双Buffer来解决时间回拨与生成性能等问题,同时结合MySQL进行ID分配。
8.Leaf
Leaf是美团开源的分布式ID生成方案,开源地址见于参考文档3。提供两种生成的ID的方式:雪花算法模式和号段模式。可通过配置文件来指定。
Leaf的雪花算法模式依赖于ZooKeeper,其workId的生成策略是基于ZooKeeper的顺序ID来生成的;号段模式也是基于数据库的号段模式+双Buffer机制实现的。












