2019-12-03 18:40:05
2019-12-03 18:40:05
每个系统模型都有自己的采集,无论是内置的还是用户自定义的系统模型,新闻系统有新闻系统采集,下载系统有下载系统采集等等。
采集常用技巧:
1、过滤文章内容的链接:
广告过滤正则设置:“<a [!–ad–]>,</a>”
2、同上得出,过滤font之类的标签:
广告过滤正则:“<font[!–ad–]>,</font>”,其他依此类推。
3、同一链接的页面如何重复采集:
到“管理采集节点”那清空节点即可重复采集已入库的页面。
4、采集内容分页正则说明:
如果是全部列表式,则只需看第一页的页面HTML代码。
采集的一些特殊字段说明:
1、“下载地址正则”、“在线观看地址正则”、“图片集正则”。
说明:下面的两个正则是分开的,并且是用“[!empirecms!]”格开。
| 下载地址正则 | 格式:地址正则([!–ecmsdownpathurl–])[!empirecms!]名称正则([!–ecmsdownpathname–]) |
| 说明:名称正则可以不设置,由系统自己命名。 | |
| 在线观看地址正则 | 格式:地址正则([!–ecmsonlinepathurl–])[!empirecms!]名称正则([!–ecmsonlinepathname–]) |
| 说明:名称正则可以不设置,由系统自己命名。 | |
| 图片集正则 | 格式:缩略图([!–ecmsspicurl–])[!empirecms!]大图([!–ecmsbpicurl–])[!empirecms!]名称([!–ecmspicname–]) |
| 说明:大图与名称正则可以不设置。 |
2、只要字段“输入表单显示元素”是“图片(img)”、“FLASH文件”、“文件(file)”均支持远程保存文件到本地。
3、“newstext”字段才支持远程保存内容里的图片和FLASH到本地。
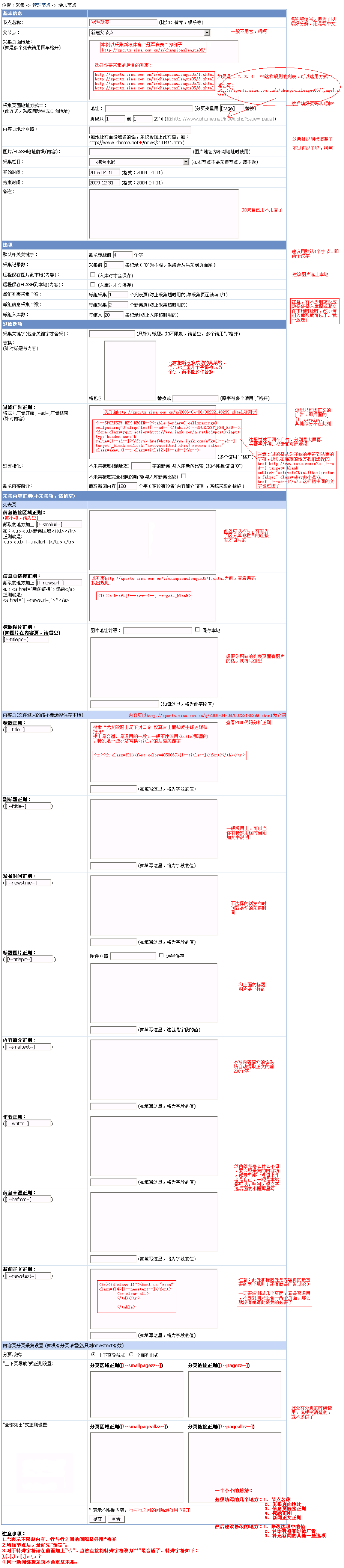
| 采集实例: |
以采集新浪体育的冠军联赛为例,如下图: