2019-05-24 07:37:54
2019-05-24 07:37:54
本文为 AI 研习社编译的技术博客,原标题 :
Customer segmentation using Machine Learning K-Means Clustering
翻译 | 吕鑫灿、就2 校对 | 就2 整理 | 志豪
原文链接:
http://www.patterns7tech.com/customer-segmentation-using-machine-learning-k-means-clustering/
Rajshekhar Bodhale | 2017年11月17日 | 机器学习
基于信息技术的大多数平台正在生成大量数据。这些数据称为大数据,它承载了大量的商业智能。这些数据互相交融以满足不同的目标和可能性。应用机器学习技术就很有可能为客户创造价值。
问题描述
- 我们在会计学和物联网领域拥有基于大数据的平台,可以持续生成客户行为和设备监控数据。
- 识别目标客户群或者基于不同维度分析(推导)模式非常关键,并且实在的为平台提供了优势。
假设你有1000个客户使用你的平台并且不断地产生体量庞大的大数据,任何关于这方面的深入见解都将产生新的价值。
作为Patterns7团队不断尝试的机器学习计划和创新事物的一部分,我们对K-Means聚类算法进行了实验,这为客户带来的价值非常惊人。
解决方案
聚类是将一组数据点划分为少量聚类的过程。在本部分中,你将理解并学习到如何实现K-Means聚类。
K-Means聚类
K-Means聚类是一种常用于将数据集自动划分为K个组的方法,它属于无监督学习算法。

K-Means目标
- K均值的目的是使每个点到其对应的聚类质心的距离的平方和最小。给定一组观测值(x1,x2,...,xn),其中每一个观测值都是d维实数向量,K均值聚类旨在将n个观测值划分为k(k≤n)个集合S={S1,S2,...,Sk}以最小化聚类内的平方和,其中µi是Si中的点的平均值。
- 保证K-Means算法收敛到局部最优。
业务用途
这是一种通用算法,可用于任何类型的分组。部分使用案例如下:
- 行为细分:按购买历史记录细分,按应用程序、网站或者购买平台上的活动细分。
- 库存分类:按照销售活动分组存货(准备库存)。
- 传感器测量:检测运动传感器中的活动类型,并分组图像。
- 检测机器人或异常:从机器人中分离出有效地活动组。
k - means聚类算法
- 步骤1:选择集群的数量K。
- 步骤2:随机选择K个点,作为质心。(不一定要从你的数据集中选择)
- 步骤3:将每个数据点分配到-> 构成K簇的最近的质心。
- 步骤4:计算并重新放置每个集群的新质心。
- 步骤5:将每个数据点重新分配到最近的质心。如果有任何重置发生,转到步骤4,否则转到FIN。
对于python,我使用的是Spyder Editor。
下面,我们将展示K-means算法如何处理客户费用和发票数据的例子。
我们有500个客户数据,我们关注两个客户特征: 客户发票,客户费用。
一般来说,只要数据样本的数量远远大于特征的数量,该算法可以用于任意数量的特征。
步骤1:清理和转换数据
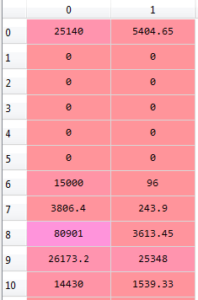
对于这个示例,我们已经清理和做了一些简单的数据转换。下面是pandas DataFrame的数据样本。
导入库,
1、numpy 即用于数学工具的,以在我们的代码中包含任何类型的数学
2、matplotlib 绘制漂亮的图表
3、pandas 用于导入数据集和管理数据集

步骤2: 我们对总费用和总发票应用聚类。在X中选择必需的列。
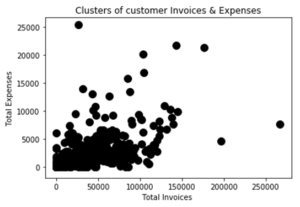
下图显示了500个客户的数据集,总发票在x轴,总费用在y轴。
步骤3:选择K并运行算法选择K
上面描述的算法找到一个特定的预先选择K的集群和数据集标签。
为了找到数据中的集群数量,用户需要运行K-means聚类算法对K个值的范围进行聚类并比较结果。一般来说,没有确定K的精确值的方法,但是可以使用以下技术得到精确的估计值。
通常用于比较不同K值之间的结果的度量之一是:
数据点与它们的集群中心之间的平均距离。
因为增加集群的数量总是会减少到数据点的距离,所以增加K总是会减少这个度量,当K等于数据点的数量时达到0的极限。因此,这个指标不能作为唯一的目标。相反,将与质心的平均距离作为K的函数绘制出来,并使用“弯头点”(急剧下降的速度)来粗略地确定K。
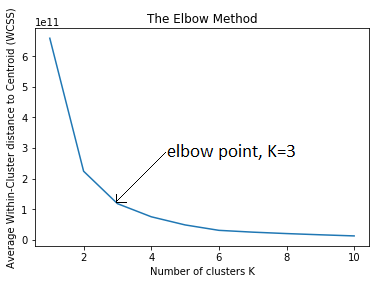
用弯头法求出最优簇数K=3。对于本例,使用Python包scikit-learn进行计算,如下所示:
# K-Means Clustering
# importing the libraries
importnumpy asnp
importmatplotlib.pyplot asplt
importpandas aspd
# importing tha customer Expenses Invoices dataset with pandas
dataset=pd.read_csv('Expense_Invoice.csv')
X=dataset.iloc[: , [3,2]].values
# Using the elbow method to find the optimal number of clusters
fromsklearn.cluster importKMeans
wcss = []
fori inrange(1, 11):
kmeans=KMeans(n_clusters=i, init='k-means++', max_iter= 300, n_init= 10, random_state= 0)
kmeans.fit(X)
wcss.append(kmeans.inertia_)
plt.plot(range(1, 11),wcss)
plt.title('The Elbow Method')
plt.xlabel('Number of clusters K')
plt.ylabel('Average Within-Cluster distance to Centroid (WCSS)')
plt.show()
# Applying k-means to the mall dataset
kmeans=KMeans(n_clusters=3, init='k-means++', max_iter= 300, n_init= 10, random_state= 0)
y_kmeans=kmeans.fit_predict(X)
# Visualizing the clusters
plt.scatter(X[y_kmeans == 0, 0], X[y_kmeans == 0, 1], s = 100, c = 'red', label='Careful(c1)')
plt.scatter(X[y_kmeans == 2, 0], X[y_kmeans == 2, 1], s = 100, c = 'green', label='Standard(c2)')
plt.scatter(X[y_kmeans == 1, 0], X[y_kmeans == 1, 1], s = 100, c = 'blue', label='Target(c3)')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 250, c = 'yellow',
label='Centroids')
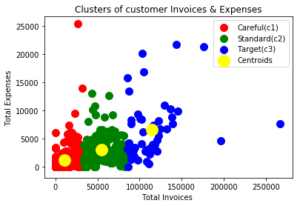
plt.title('Clusters of customer Invoices & Expenses')
plt.xlabel('Total Invoices ')
plt.ylabel('Total Expenses')
plt.legend()
plt.show()
步骤4:查看结果
下面的图表显示了结果。
- “谨慎型客户”谁的收入越少,他们花的也就越少。
- “一般客户”收入是平均的,他们花得更少,
- “目标客户”是谁的收入更多,他们花得更多。