 2019-07-18 19:57:50
2019-07-18 19:57:50
Robots文件相信做网站的人们多少都有接触过,Robots文件就是我们网站根目录里的Robots.txt文件,Robots.txt文件是一种搜索协议,被简称为“Robots协议”,搜索引擎蜘蛛进入我们网站以后会第一时间查看Robots.txt文件里面的Robots协议,这个Robots协议就是用来告诉搜索引擎蜘蛛我的网站那些东西看以收录回去,那些东西他们不可以收录,简单的说就是“我的网站我做主”,我允许的你才可以抓取。

Robots文件屏蔽搜索引擎蜘蛛抓取的典型案例
给大家举个例子吧,大家都知道淘宝吧?而淘宝就使用Robots文件屏蔽了大部分的搜索引擎蜘蛛抓取,因此我们在百度搜索淘宝的时候,看到就是下面这样的情况,淘宝之所以要使用Robots协议屏蔽搜索引擎蜘蛛的抓取,是因为淘宝不希望自己的商业信息被窥探,而且这样也可以让用户更加依赖淘宝内部的搜索,停留在淘宝内部。
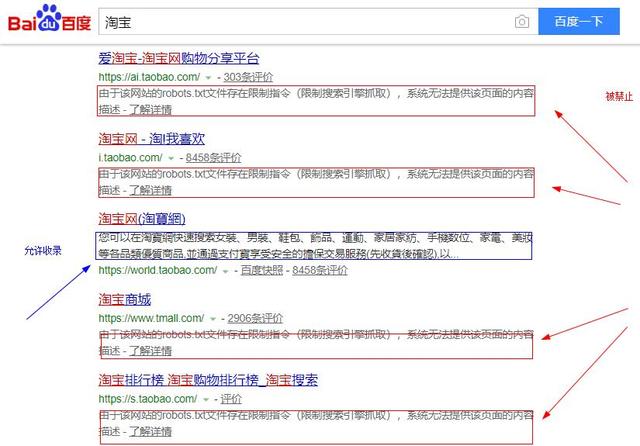
具体淘宝为啥要使用Robots去屏蔽搜索引擎蜘蛛抓取我们在这就不妄自揣测了,相信肯定是有原因的,我们从上图可以清楚的看到红色箭头指示的类目的内容是被淘宝设置了Robots协议禁止抓取的,而蓝色箭头所指示的类目是淘宝没有在Robots.txt文件里面写明禁止抓取的,因此我们可以看到蓝色框里面有一些淘宝网的文字介绍。
网站必须设置Robots文件吗?六六站长觉得未必

前面我们也说了Robots文件是用来约束搜索引擎蜘蛛的,但是这个Robots.txt文件我们网站真的必须设置吗?大家都知道我们的网站流量主要还是来自搜索引擎,而我们又不像淘宝,而且搜索引擎蜘蛛现在也高度的智能化,他所抓取回去的东西也会进行筛选,符合要求后才会在搜索引擎进行建库索引。
既然我们依靠搜索引擎的流量,那么我们就应该对搜索引擎敞开怀抱,让他在我们的网站自由的爬行,他尽可能多的将我们网站的内容抓取走才符合我们的需要,知道了这一点我们就知道Robots文件的存在有没有必要了,当然了这也需要我们对我们自己的网站足够了解,如果我们网站确实有些内容或者页面不希望被搜索引擎抓取,那么我们就可以通过设置Robots协议去禁止搜索引擎的抓取。

我们在从另一方面说说我们网站需不需要设置Robots文件吧,Robots.txt里面的Robots协议是有规范的书写形式的,例如:Disallow: 是禁止抓取,Allow: 是可以抓取,所以有很多新手站长就会搜索“Robots协议怎么写”这样的问题去学习,反而网站设置Robots文件成了一个麻烦,写不好的可以导致网站出现各种问题,所以网站设置Robots文件还不如删除掉。不知道大家的网站有没有设置熊掌号,如果设置了不知道大家有没有留意他的任务中心里有一个答题任务就是关于Robots文件的,回答正确的话就是网站不设置Robots文件。
最后我们再聊聊Robots协议究竟该怎么写
Robots协议怎么写,其实我们在网上简单的了解一下也会学会了,这面有三个必要重要的书写开头“User-agent: ”、“Disallow: ”、“Allow: ”。User-agent:是用来定义Robots文件的,一般书写为User-agent: *即可,另两个我们在上一段已经说过是什么作用了,所以在这里我们直接说如何使用,例如我想禁止某个页面或者某个目录被搜索引擎抓取,我就可以书写为“Disallow: xxx.com/xxx/x.html”或者“Disallow: /admin/”。而“Allow: ”的运用其实也是这种意思,例如上面说到的淘宝网,他就是把大部分页面都使用Robots协议做了屏蔽,而只允许了某一个或者某一些页面允许抓取,所以他就只需要在Robots.txt写入“Allow:某个页面或者某些页面的网站根目录 ”的Robots协议即可。
Robots协议写法
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
写到最后
好了今天关于网站的Robots文件就写到这里了,希望这篇文章对你有所帮助,当然了如果大家遇到什么关于Robots协议该怎么写的问题也可以在下面的留言处给我留言,我会在看到的第一时间回复给大家的,好了今天66分享网(六六站长)继续研究下一篇文章该跟大家讲讲那些知识了。












