 2019-08-03 20:58:30
2019-08-03 20:58:30
编译 | xyhncepu
编辑 | Pita
尽管近年来利用 Transformer 模型进行神经机器翻译(NMT)取得了巨大成功,但是 NMT 模型对输入的微小干扰仍然很敏感,从而导致各种不同的错误。谷歌研究院的一篇 ACL 2019 论文提出了一种方法,使用生成的对抗性样本来提高机器翻译模型的鲁棒性,防止输入中存在的细小扰动度对其造成影响。结果表明,该方法提高了 NMT 模型在标准基准上的性能。在本文中,作者 Yong Cheng、 Lu Jiang 和 Wolfgang Macherey 对其在 ACL 2019 上发表的《具有双对抗性输入的鲁棒神经机器翻译》论文进行了介绍。
Robust Neural Machine Translation with Doubly Adversarial Inputs
- 论文阅读地址:https://arxiv.org/abs/1906.02443
近年来,利用 Transformer 模型进行神经机器翻译(NMT)取得了巨大的成功。基于深度神经网络的 NMT 模型通常在非常大的并行语料库(输入/输出文本对)上以完全数据驱动的方式进行端到端训练,而不需要强制使用显式的语言规则。
NMT 模型尽管取得了巨大的成功,但它对输入中存在的微小干扰仍然很敏感,这就会导致它出现各种不同的错误,如翻译不足、翻译过度或翻译错误。例如,给定一个德语句子,最先进的 NMT 模型 Transformer 会生成正确的翻译:
- 「Der Sprecher des Untersuchungsausschusses hat angekündigt, vor Gericht zu ziehen, falls sich die geladenen Zeugen weiterhin weigern sollten, eine Aussage zu machen。」
- 机器翻译成英语的结果:「Machine translation to English:「The spokesman of the Committee of Inquiry has announced that if the witnesses summoned continue to refuse to testify, he will be brought to court(调查委员会发言人宣布,如果被传唤的证人继续拒绝作证,他将被带到法庭)」。
但是,当我们对输入语句进行细微的更改时,比如将 geladenen 换成同义词 vorgeladenen,翻译就会变得非常不同(在这个例子中翻译结果是错误的):
- 「Der Sprecher des Untersuchungsausschusses hat angekündigt, vor Gericht zu ziehen, falls sich die vorgeladenen Zeugen weiterhin weigern sollten, eine Aussage zu machen。」
- 机器翻译成英语的结果:「The investigative committee has announced that he will be brought to justice if the witnesses who have been invited continue to refuse to testify(调查委员会宣布,如果被邀请的证人继续拒绝作证,他将被绳之以法)」。
由于 NMT 模型缺乏鲁棒性,导致其在许多不能承受其不鲁棒性的商业系统难以得以实际应用。因此,学习鲁棒翻译模型不仅是很有价值的,也是许多场景应用所要求的。然而,虽然神经网络的鲁棒性在计算机视觉领域已经得到了广泛的研究,但是相关文献中对学习鲁棒 NMT 模型的研究却很少。
在《具有双对抗性输入的鲁棒神经机器翻译》一文中,我们提出了一种方法,即使用生成的对抗性样本来提高机器翻译模型的鲁棒性,以防止输入中存在的细小扰动度对其造成影响。我们学习了一个鲁棒 NMT 模型,以直接利用模型知识和扭曲模型预测的意图来克服对抗性样本。结果表明,该方法提高了 NMT 模型在标准基准上的性能。
用 AdvGen 训练模型
一个理想的 NMT 模型将会对存在微小差异的独立输入生成相似的翻译结果。我们方法的思想是使用对抗性输入来干扰翻译模型,以期提高模型的鲁棒性。它使用一种称为对抗生成(AdvGen)的算法来实现上述方法,该算法生成可信的对抗样本来扰乱模型,然后将它们反馈到模型中进行防御训练。虽然该方法的灵感来自于生成对抗网络(GANs)的思想,但它并不依赖于鉴别器网络,而是简单地将对抗性样本应用于训练中,有效地实现了训练集的多样化及扩展。
第一步是使用 AdvGen 干扰模型。我们首先使用 Transformer 根据源输入句、目标输入句和目标输出句计算翻译损失。然后 AdvGen 随机选择源句子中的一些单词,假设它们是均匀分布的。每个单词都有一个相似单词的关联列表,例如单词 「candidates 」可用以代替 「substitution」使用,AdvGen 从中选择最可能在 Transformer 输出中引发错误的单词。然后,这个生成对抗性语句被反馈给 Transformer,然后 Transformer 进而对其启动防御阶段。

图 1:首先,将 Transformer 模型应用于输入句(左下),并与目标输出句(右上)和目标输入句(右中;从占位符「<sos>」开始)相结合,从而计算翻译损失。AdvGen 函数将源句子、单词选择分布、单词「 candidates 」和翻译损失作为输入,构造一个对抗性源样本。
在防御阶段期间,对抗性语句会被反馈到 Transformer 模型中。Transformer 再次计算翻译损失,但这次使用的是对抗性源输入。利用上述方法,AdvGen 使用目标输入句、单词替换 「 candidates 」、注意力矩阵计算的单词选择分布和翻译损失构建了一个对抗性目标样本。

图 2:在防御阶段,对抗性源样本作为 Transformer 模型的输入,用来计算翻译损失。然后,AdvGen 使用与前面相同的方法从目标输入生成一个对抗性目标样本
最后,将对抗性语句被反馈到 Transformer 中,并利用对抗性源样本、对抗性目标输入样本和目标语句计算鲁棒性损失。如果扰动导致了显著的损失,则将损失最小化,这样当模型遇到类似的扰动时,就不会犯同样的错误。另一方面,如果扰动导致的损失较小,则什么也不会发生,这表明模型已经能够处理这种扰动。
模型的性能
通过将该方法应用于标准的汉英和英德翻译基准中,证明了我们的方法是有效的。与竞争性 Transformer 模型相比,我们观察到 BLEU 值分别显著提高 2.8(汉英翻译)和 1.6(英德翻译),获得了新的最佳性能。

图 3:与 Transformer 模型(Vaswani 等人,2017 年)在标准基准上的对比
然后,我们在一个噪声数据集上评估我们的模型,该数据集使用类似于 AdvGen 描述的过程生成。我们使用一个干净的输入数据集,例如在标准翻译基准上使用的数据集,并随机选择用于相似单词替换的单词。我们发现,相比其他最近的模型,我们的模型显示出更好的鲁棒性。
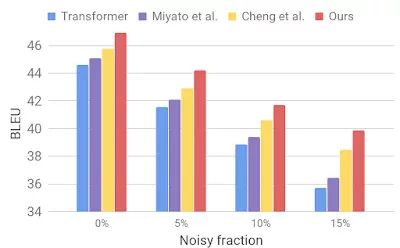
图 4:与 Miyao 等人(论文链接:https://arxiv.org/abs/1605.07725)和 Cheng(论文链接:https://arxiv.org/abs/1805.06130)等人在人工噪声输入的 Transformer 模型比较
结果表明,我们的方法能够克服输入语句中的小扰动,提高泛化性能。它的性能要比同类的翻译模型更优,并在标准基准上实现了最先进的翻译性能。我们希望我们的翻译模型可以作为一个鲁棒构建模块来改进许多下游工作,特别是那些对存在瑕疵的翻译输入具有敏感性或难以容忍的工作。
致谢
本研究由 Yong Cheng、 Lu Jiang 和 Wolfgang Macherey 完成。另外要感谢我们的领导 Andrew Moore 和 Julia(Wenli)Zhu。
Via:https://ai.googleblog.com/2019/07/robust-neural-machine-translation.html












