 2019-06-01 13:32:21
2019-06-01 13:32:21
圆栗子 发自 凹非寺

谷歌数据集搜索工具,上线了。
在发布这个消息的博客里,团队大概表达了这样的意思:
现在啊,许多领域的科学家,每天呼吸的不是空气,是数据集。没有数据集,他们就活不下去。

△唯有数据集,能救命
不过,数据集分散在世界的各个角落,口口相传是最常用的传播途径。
谷歌想让搜索数据集,能像在Google Scholar上搜索论文那样容易。
如此,便有了GoogleDataset Search。
猫喜欢什么口味的冰淇淋?
这样一来,不论是哪里发布的数据集,谷歌一下就出来了。
连使用方法都有,你又少了一个不好好训练网络的理由。
所以,一起来试一下吧。在下是按衣食住行四类,分别搜索的。
·衣·
穿着的部分,搜的是胖次pants:

然后,就出现了墨西哥、秘鲁、哥伦比亚,各个国家关于裤子的数据集。
比如,从棉裤的视角,可看墨西哥的经济状况。
·食·
吃的东西,搜了ice cream:

最吸引人的,当然不是各国的冰淇淋生产力。
猫在哪个年纪,喜欢哪种口味的冰淇淋,果然有 (mei) 些 (sha) 研究价值。
·住·
就看北京房价吧,搜索beijing house price:
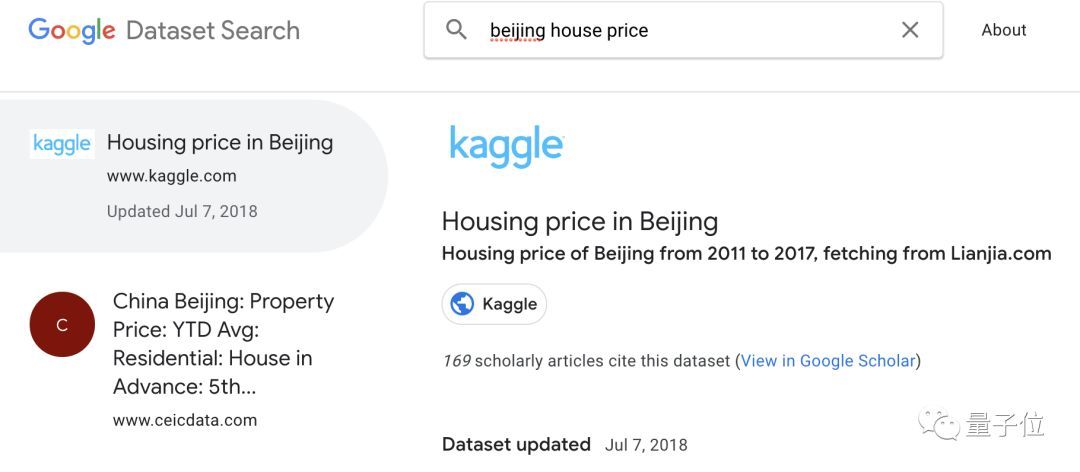
第一条结果来自Kaggle,是链家2011到2017年的数据。
这数据集的杀伤力,应该还是很大的。有兴趣的大家,可以自行观察。
传送门:https://www.kaggle.com/ruiqurm/lianjia
·行·
感觉出行服务、共享单车,也不会有什么惊喜。就搜了个horse:
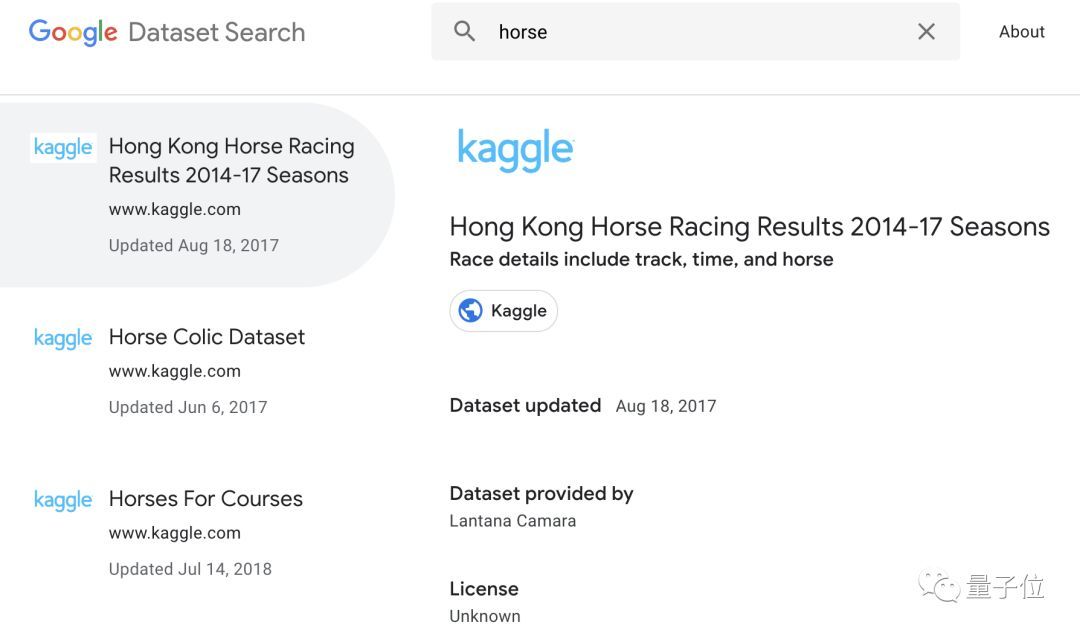
当然,搜出香港赛马的数据,也并不惊喜。
第二条,是关注马体健康状况的疝气数据。曾经有项研究,用疝气预测马的死亡概率。
数据集里,也有大千世界,各位不妨自己去搜一搜。
数据集搜索,不是一天建成的
为了搭好这个搜索工具,谷歌团队给提供数据集的人们,准备了一份充满关怀的指南。
这样一来,大家对贡献的数据集,就能有个统一的描述方式:
· 谁创建了数据集?
· 什么时候发布的?
· 数据怎样收集的?
· 使用方法是什么?
……
信息一项一项填好,搜索工具才能更友好。
描述的时候,只要依照Schema.org的标准词汇表,就可以了。
谷歌把信息收集起来之后,就会去分析,一个数据集的不同版本,可能在哪些地方。
除此之外,还要看看有哪些论文(或者其他出版物) ,提到过这个数据集。
谷歌团队说,这一版已经支持多种语言。更多语言的支持也已经在路上了。
比如,想要自我打击的话,现在可以直接搜索“中国房价”。

普通谷歌搜索,也能搜数据表格
谷歌在数据集上做过的事情,远不止Dataset Search这个工具这么简单。
除此之外,团队也为人类最常用的谷歌搜索,加入了表格数据搜索的能力。

△进化前 vs 进化后 (右)
就像这样,已经可以搜索出谷歌基金会 (Google Foundation) 2014的总开支。
不过谷歌说,现在的这些努力结果,还是不够好。
他们希望,未来不论是科研领域、政府部门、新闻机构,还是任何各行各业,都有源源不断的数据,能从谷歌的平台上搜索出来。
意思就是,能提供数据集的大家,快到碗里来。












