 2019-06-01 13:32:42
2019-06-01 13:32:42
一年一度的KDD今年于8月19日至23日在英国伦敦开幕。作为数据挖掘的国际顶级会议,每年都会吸引包括谷歌、微软、阿里巴巴等世界顶级的科技公司参与,蚂蚁金服也不例外。
KDD的全称是ACM SIGKDD Conference on Knowledge Discovery and Data Mining。KDD 2018在伦敦举行,今年KDD吸引了全球范围内共 1480 篇论文投递,共收录 293 篇,录取率不足 20%。蚂蚁金服也有多篇文章入选。
问题来了,这些论文地址在哪里下载?请关注本账号“蚂蚁金服科技”,在公众号对话框内回复“KDD”,即可获得论文下载包哦!祝学习愉快!
此外,在过去的一年中,蚂蚁金服也多次亮相国际各类顶级学术会议,包括AAAI,NIPS,ICML,CVPR,ACL(可直接点击链接阅读哦)等等,为学界带来了诸多结合实际业务场景的创新研究和应用。对蚂蚁金服而言,在顶级学术会议上发布论文,有两方面的意义,一个是推进人工智能最前沿研究的发展,同时紧密地把学术与应用场景结合起来。而蚂蚁金服拥有海量的应用场景,这些技术从研究到落地能够真正造福数以亿计的用户,真正为世界带来平等的机会。
本文分别解读了蚂蚁金服本次入选KDD的三篇优秀论文,给大家分享数据挖掘+人工智能是如何保护大家账户安全、识别保险欺诈、对用户进行个性化推荐的。一起来学习一下吧~

一、“谁吃了运费?” 基于图学习的运费险诈骗识别
论文标题:
Who-Stole-the-Postage?Fraud Detection in Return-Freight Insurance Claims
作者:梁琛,刘子奇,刘斌,周俊、李小龙
论文地址:
https://github.com/chenlianMT/Who-Stole-the-Postage-/blob/master/return-freight-insurance.pdf
1.1 前言
在线购物中,运费险几乎成了剁手必备的订单伴侣——它能让买家放心购物,不用担心“货不对板”想要退货时还需要承担退货的运费。然而大规模的运费险单量,也催生了不少的骗保产业。
本文在传统运费险风控的基础上,详细介绍了蚂蚁金服人工智能部如何用图学习的方法,抓取更多的骗保行为。
经常在网上购物的朋友,可能对运费险已经很熟悉了:买了衣服却有色差、冲动消费之后却后悔、在其他店看到了更便宜的商品,在这些情境下,退货是买家常见的诉求。随着网上购物的兴起,退货的运费究竟由买家、还是卖家出资,争议量巨大,单纯依靠客服小二解决这些争议是不现实的。为了保障买家对购物行为的“后悔权”,运费险应运而生。
购买运费险后,在确认收货前,买家可以要求退货。退货所需要的运费,需要承保公司来承担。大部分的运费险,购买一单只需要几毛钱,但退回的运费却有几块钱。如果实际退货没有发生,或实际退货所需运费成本低于保险公司的赔付额,用户可以得到数倍收益。针对运费险的骗保活动也应运而生。
由于每天运费险理赔单量级巨大,人工核赔每个理赔单是否存在恶意骗保行为是不可行的。传统的运费险风控,主要通过一组策略,在线对单个账户的风险等级进行评估。基于策略、着眼单个账户,往往不能覆盖所有的骗保活动;本文将重点放在了构建账户关系网络(即关系图),用神经网络的方法,挖掘关系图中的信息。
本文将骗保识别问题,定义为一个账户的二分类问题,二分类的标注来自运费险风控的策略。在解决这个问题的过程中,我们发现,行为特征(购物行为、浏览行为等)不能有效地区分“正常账户”和“骗保账户”。这主要是因为骗保的手段是专业的、变化的、有意遮掩的。然而,账户之间的关系,往往更加稳定,更加难以隐藏。但是如何构建账户之间的关系,让“正常账户”和“骗保账户”的区分度更高呢?
以下是我们尝试的三种构图方式:
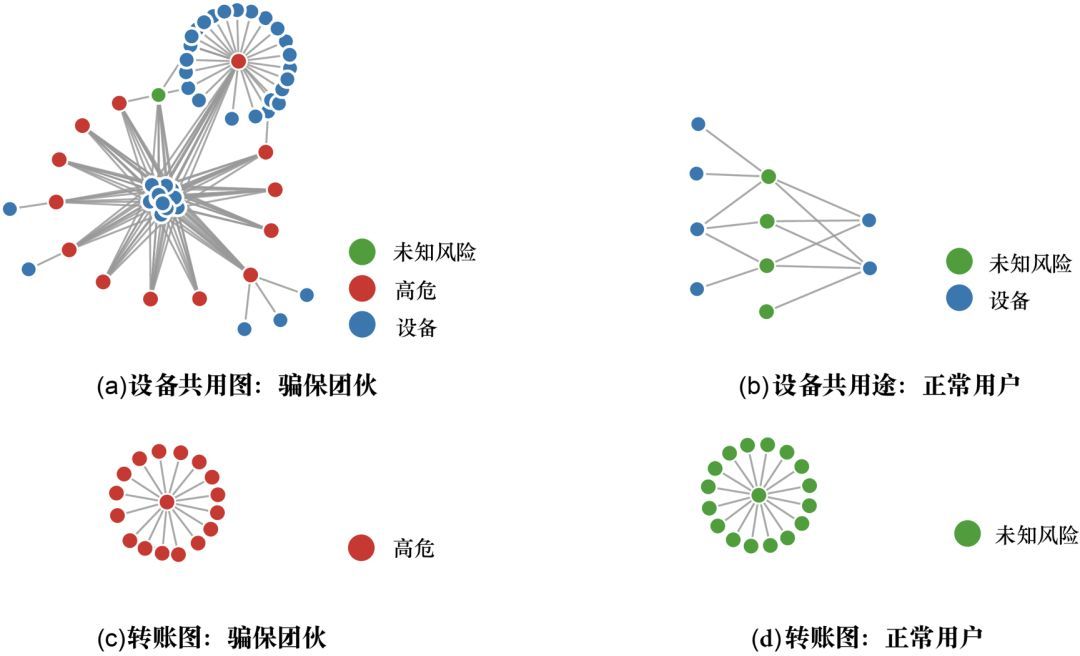
转账图中,每个节点均为一个账户,刻画了支付宝中的转账行为。设备共用图中,包括账户和设备两种节点,如果一个账户曾在某设备上登录,则这个账户和设备之间就有一条边。
可以观察到,设备共用图中“正常用户”和“骗保团伙”的关系模式区别较大。我们最终选择了设备共用图作为构图对象。
在拿到图和行为特征后,一个自然的选择是Graph Neural Networks (GNNs) [1]算法。GNNs是一类能够学习图中节点信息的算法。GNNs算法中的每个节点,通过学习自己邻居的特征,不断循环,更新自己原本的特征。在几轮更新之后,图中的节点就会包含周围很多邻居的信息。即在第k次更新中,节点v的信息为:
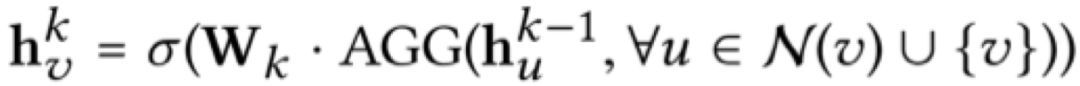
其中u为节点v本身或它的邻居,AGG为学习邻居信息的公式(比如直接相加等),sigma为激活函数。
在运费险工作中,我们使用了基于GNNs思想的GeniePath算法[2]。GeniePath自适应的选择有价值的邻居信息做信息集成AGG,比如选择与自己节点相似的邻居节点。即:
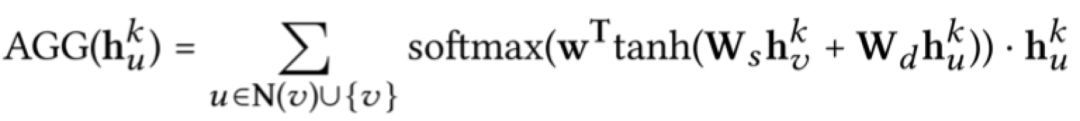
比如有三个互相关联的账户,其中两个经常深夜活动,且注册时间极短,另外一个账户行为正常。那么,我们能合理地认为前两个账户之间的关联性更强。
在运费险数据上,用GeniePath图学习方法、node2vec [3]无监督图学习方法、GBDT [4] 非图学习方法进行对比试验,发现GeniePath的F1更好,即GeniePath对策略的拟合更好。同时,GeniePath额外抓取的黑产,占策略抓取黑样本的35%以上,黑样本总数提高了相当可观的数量。经过专家采样评估,真实黑样本的精度高于40%,相比GBDT方法有20%以上的提升。
1.2 总结
至此,我们总结了运费险欺诈问题中的如下问题:(1)如何构图;(2)如何高效判别图中的分类;(3)如何评价各算法的有效性。希望本文的思路能对其他反欺诈工作带来一定的参考。
1.3 参考文献
[1] Hamilton W, Ying Z, Leskovec J.Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems 2017 (pp. 1025-1035).
[2] Liu Z, Chen C, Li L, Zhou J, Li X, Song L. GeniePath: Graph Neural Networks with Adaptive Receptive Paths. arXiv preprintarXiv:1802.00910. 2018 Feb 3.
[3] Grover A, Leskovec J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining 2016 Aug 13(pp. 855-864). ACM.
[4] Chen T, Guestrin C. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining 2016 Aug 13 (pp. 785-794).ACM.
二、GeniePath: 会自动过滤多度“邻居”的图神经网络
论文标题:
GeniePath: Graph Neural Networks with Adaptive Receptive Paths
作者:刘子奇、陈超超、李龙飞、周俊、李小龙、宋乐
论文地址:
https://arxiv.org/abs/1802.00910
2.1 概述
本篇论文主要目的是介绍一种新的图神经网络(Graph Neural Networks, GNN)方法,GeniePath[4]。用一句话说:GeniePath沿用GNN的计算框架,其特点在于会根据优化目标自动选择有用的邻居信息,来生成节点特征(embedding)
2.2图神经网络(GNN)是什么?能做什么?
2.2.1 GNN能做什么?
一个机器学习任务是这样的:我们假设有个上帝才知道的ground truth函数
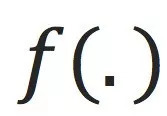
,上帝随机生成一些数据
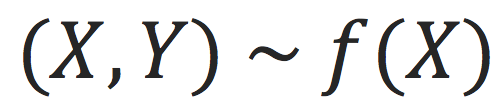
。我们只能观测到数据
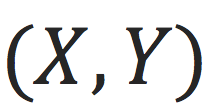
,但是不知道那个ground truth函数是什么。我们希望使用机器学习算法从观测到的数据
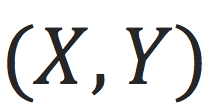
学一个函数
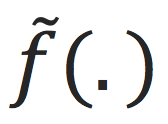
,希望
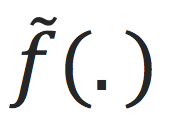
可以在unseen数据上work的好,即
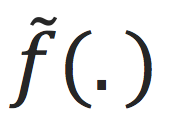
逼近。
那么,我们要看一个机器学习模型
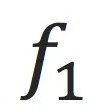
是否能做某事、或者能比另一个模型
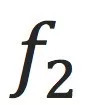
做的好,可以从两个点出发:
1.
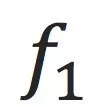
是否在测试数据上work的比
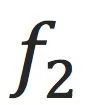
好?这是一个经验指标,只能通过更多的数据和实验来验证;
2.如果我们提前就知道上帝才知道的那个函数,那么我们看和谁能表达的解空间?谁能表达那个最优的解空间,就更有可能得到更优的解。(注:实际中即便能表达最优解也不一定能解出最优解,涉及优化理论,这超出本文范围)。
那么好,我们下面先找个栗子,通过方式2验证:假设我们随机生成很多联通子图,即

。我们用上帝知道的那个函数(一个节点的打标

是节点所在联通子图的大小,即所在联通子图的节点数目)构成的一个训练数据集。对于机器学习算法来说,算法只是给定了这些训练数据,并不知道这些节点上的打标是怎么生成的。我们希望通过训练数据学一个函数,能够在新的待预测图数据上预测的好,即逼近。
例如,下图中我们的训练数据有5个节点以及对应的打标,我们有可能学一个GBDT?一个DNN?通过构建适当的特征,并对测试数据做预测吗?

图1. 联通图例子。左侧是训练集,包括5个节点,每个节点的打标是该节点所在联通子图的大小。右侧是测试数据。
答案是:这比较难。因为:(1)这些方法都是单纯的考虑一个节点的特征;(2)怎么把拓扑中相关的节点信息做成特征很难。
是否图神经网络(GNN)方法可以?我们先来看看如下计算过程,然后引入图神经网络的计算:

图2.联通图例子使用图神经网络计算
我们进行了以下几步:
(1)先对训练数据构建邻接矩阵
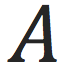
(注意:需要带自环);
(2)对邻接矩阵做归一化
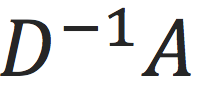
(是对角阵,每项代表节点邻居数)
(3)乘无穷次得到稳态转移概率;
(4)element-wise对矩阵每项做step function
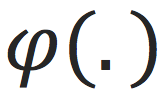
,即 [0 if <=0 else 1]
(5)按行求和,最终我们得到的向量即对每个节点的打标。那么我们可以总结这个计算过程为:
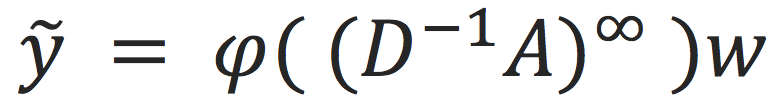
,其中

。这个函数有唯一参数
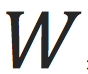
。我们一开始随机初始化
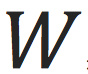
,然后不断计算损失
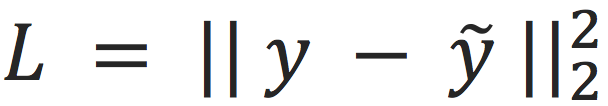
,就可以优化
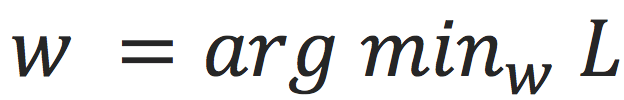
。那么这个函数和图神经网络有什么关系呢?
2.2.2 GNN的计算模式
回顾上一小节,之所以函数
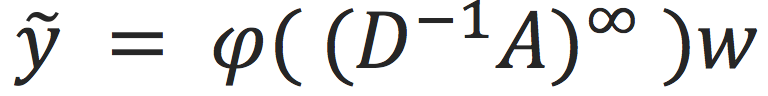
能够解决联通图大小计算问题,最关键一步就是迭代
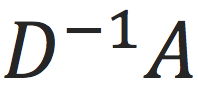
多次(设为
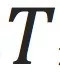
次)。通过这个迭代,GNN可以传播
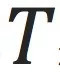
跳以内节点的信息(在上面的栗子里面是为了计算节点之间传播次是否可达)。而这也是图神经网络计算的关键所在。
下面我们引入一些重要的标记:图神经网络模型的只有两个输入:节点之间构成的邻接矩阵
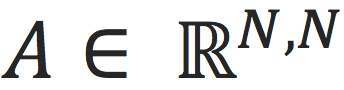
,以及节点对应的特征

,其中

表示节点数目,
表示特征维度。即
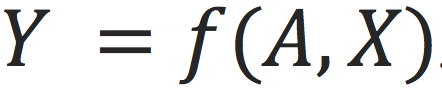
。
下面我们看看常用的图神经网络的表达式:

(1)
其中上标表示第次迭代;
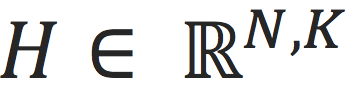
表示

个节点的
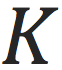
维隐含特征(embedding),其中
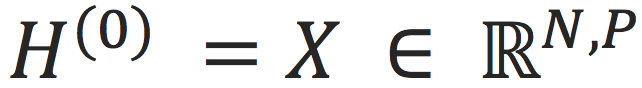
对应个节点的
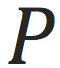
维原始特征;是模型的参数;
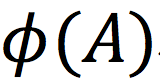
代表对
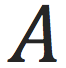
的某个固定变换,比如
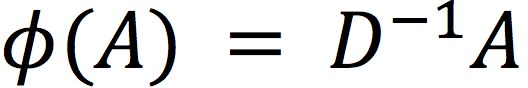
。这是一个较为强大的非线性的表达,因为每次迭代我们都增加了非线性激活函数
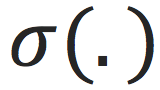
。
至此,如果式(1) 只保留最后一层激活函数,以及做无穷次迭代,当输入特征数据人工设为

N维的one-hot特征矩阵),参数通过优化估计为
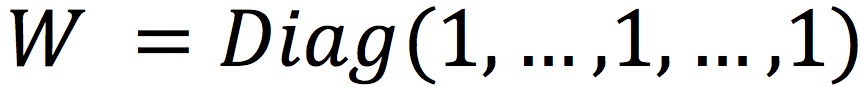
时,式(1) 可以得到最优的目标函数
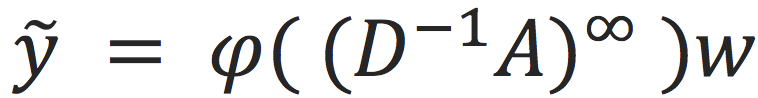
。
至此,图神经网络GNN通过这种迭代的计算范式刻画图中节点之间的关系:

2.2.3 小结
通过上面的例子,我们展示了一个图神经网络如何计算一个简单的任务。在这个例子里,GNN的解空间是DNN等方法无法触及的。想必大家能够get到一点东西。我们有如下总结:当计算目标需要节点特征、节点所在图的拓扑信息时,我们可能需要借助图神经网络的能力。
2.3 GeniePath的特点——GNN经典方法对比
目前所有的图神经网络方法都基于如下框架,做T次迭代,相当于每个节点拿自己走T跳可达的“邻居”节点,来做传播和变换,最后的被用来直接参与到损失函数的计算,并通过反向传播优化参数。

注意:各个方法的区别仅在于For循环内部的不同,即encoding过程的不同;所有的方法都不限制损失函数的形态,所以我们不会去比较这部分。
2.3.1 经典方法解决如何AGG邻居的问题
即定义不同算子整合和变换邻居信息,生成节点特征。

2.3.2 GeniePath解决AGG哪些邻居的问题
以上图神经网络存在的共同特点是:这里面定义的AGG算子,是对T跳内所有邻居做AGG,且以固定的权重做AGG。我们称计算一个节点的embedding所需的“邻居”为感知域。那么我们的问题是真的需要对T跳内所有的邻居都做AGG吗?
我们先看看这些操作是怎么对T跳邻居做AGG的。以AGG = mean operator为例,即:
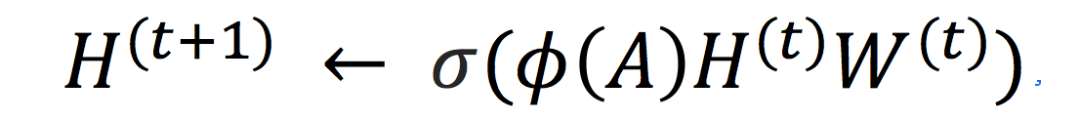
如果去掉激活函数(便于分析和展示),迭代次,我们可以得到如下线性代数表达:
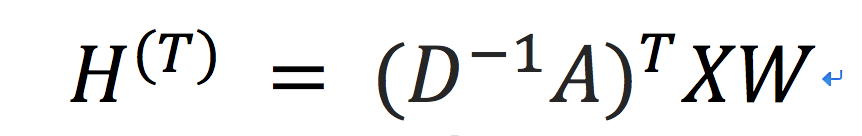
那么其实该计算定义的感知域就是
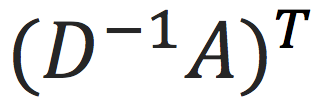
。什么意思呢?就是该感知域完全定义了每个节点最终embedding是由哪些邻居AGG生成的,且他们的贡献分别是在构好图时就已经定义好的。回到之前的例子(图1),就相当于:

上面的例子告诉我们,对于每个节点,T跳能达到的邻居节点都有用,且以上面的权重衡量。
我们真的需要对T跳内所有邻居都在这样预先定义好的感知域上做训练和预测吗?答案是:其实这可能并不最优。原因有很多,比如:图数据往往是有噪声的。比如下面关于账户安全的图数据。

光凭图信息,我们会认为绿色未知风险账户和这么多“高危”账号有关系,肯定也是“黑”账号。然而实际中,由于用户刷机、共享共同IP代理等会使得图数据携带大量噪声。我们不但要看拓扑信息还要看节点的行为特征。而经典的GNN方法只会根据拓扑信息选择邻居并AGG生成特征,不会过滤和筛选有价值的邻居。
GeniePath关心在AGG的时候到底应该选取哪些重要的邻居信息、过滤那些不重要的节点信息。示例见图4,以黑色节点为目标节点,GeniePath并不AGG所有2跳邻居信息,而是有选择的选某个子图。

图4.自适应的感知域示例
这样,问题变成了如何为每个目标节点探索某个重要的子图。GeniePath通过定义两个parametric函数:自适应广度函数、和自适应深度函数,共同对子图进行广度、深度搜索。其中自适应广度函数限定朝哪个方向搜索重要节点,自适应深度函数限定搜索的深度,即是1跳邻居信息就足够了,还是需要多跳邻居信息。
如何做AGG,这个GeniePath并不关心,当然,我们可以使用之前GraphSAGE定义的有用的AGG。即GeniePath和经典GNN方法正交。
这里我们总结GeniePath的算法为如下框架:

实现中,我们使用一个attention网络表达自适应广度函数

、使用一个LSTM-style网络表达自适应深度函数

。
2.3.3 GeniePath的效果
GeniePath在一些公开数据集上表现出的效果很有竞争力,例如:在一个著名的蛋白质网络Benchmark数据上,相比Bengio在2017年最新的graph attention networks [5],将F1提升了20% (在不使用resnet[6]的条件下)、7%(使用resnet)。详情请戳下面论文链接:
https://arxiv.org/abs/1802.00910
这里,我们展示了在一个蛋白质网络中学习到的感知域,和用GCN预定义好的感知域的对比:

图5.GCN的感知域

图6.GeniePath的感知域
图5、6中,我们展示了以黑色节点为目标节点(GCN分类错而GeniePath分类对的样本点),其2跳邻居形成的感知域。绿色边代表权重小于0.1的边,蓝色代表权重为0.1~0.2之间的边,红色表示权重大于0.2的边。从两个模型对感知域的对比来看,很明显,GCN将大部分邻居都认为是差不多同等重要的,而GeniePath则选出其中非常重要的红色的路径(邻居)。
2.4总结
GeniePath作为一个通用图神经网络算法已经在蚂蚁金服的风控场景实际使用,并得到较理想的效果,极大地提高了支付宝保护用户账户安全的能力。

2.5 参考文献
[1] Dai H, Dai B, Song L. Discriminative embeddings of latent variable models for structured data. InInternational Conference on Machine Learning 2016 Jun 11 (pp. 2702-2711).
[2] Kipf TN, Welling M. Semi-supervised classification with graph convolutional networks. arXiv preprintarXiv:1609.02907. 2016 Sep 9.
[3] Hamilton W, Ying Z, Leskovec J.Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems 2017 (pp. 1025-1035).
[4] Liu Z, Chen C, Li L, Zhou J, Li X, Song L.GeniePath: Graph Neural Networks with Adaptive Receptive Paths. arXiv preprintarXiv:1802.00910. 2018 Feb 3.
[5] Velickovic P, Cucurull G, Casanova A,Romero A, Lio P, Bengio Y. Graph attention networks. arXiv preprintarXiv:1710.10903. 2017 Oct.
[6] He K, Zhang X, Ren S, Sun J. Identity mappings in deep residual networks. In European conference on computer vision 2016 Oct 8 (pp. 630-645). Springer, Cham.
三、分布式协同哈希算法及其在蚂蚁金服中的应用
论文标题:
Distributed Collaborative Hashing and Its Applications in AntFinancial
作者:陈超超、刘子奇、李龙飞、周俊、李小龙
论文地址:
https://arxiv.org/abs/1804.04918
3.1前言
协同过滤,特别是矩阵分解模型,已经在个性化推荐中广为应用。使用它来做个性化推荐的主要过程如下:(1)线下训练阶段,根据已有的用户——物品交互历史,学习用户和物品的潜在偏好向量;(2)线上打分排序阶段,根据学习好的用户和物品的潜在偏好向量,来预测未知的用户——物品偏好。如图1所示。

图1:矩阵分解模型过程
正所谓“天下武功,唯快不破”,在推荐系统中,模型的时率性尤为重要。从图1可知,在实际应用的推荐模型中,模型效率主要包括线下的模型训练效率以及线上的用户——物品打分排序效率。而现有的因子分解模型主要存在以下两个憋端:
(1)线下模型训练较低,现有的因子分解模型,大多都是基于单机或简单的多机并行实现的,在用户和物品量级很大的时候,将会很难完成训练,或者训练的效率极低;
(2)线上进行推荐的时候,首先需要根据用户——物品的潜在向量计算用户——物品评分,然后对评分进行排序并推荐,效果低下。
本文中,针对以上两个弊端,我们提出了两种相应的解决方案,即:
(1)使用参数服务器分布式学习框架,来进行线下模型的训练,能支持大规模用户和物品,同时能快速完成模型的训练;
(2)使用哈希矩阵分解取代原有的实数向量矩阵分解,得到用户和物品潜在哈希向量,即向量中每个元素都是二元值,线上打分可以通过哈希表查找或者计算机异或等操作迅速完成。
我们将介绍模型训练,基于参数服务器框架实现的细节,对比实验,及在蚂蚁金服中的应用。
3.2模型介绍
3.2.1 符号定义
我们使用
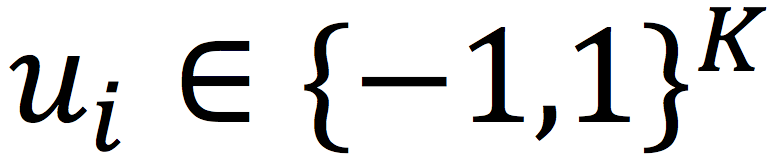
来表示用户i的K维哈希向量,使用

来表示物品j的K维哈希向量,
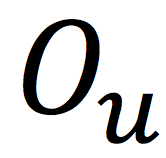
表示训练集的用户集合,
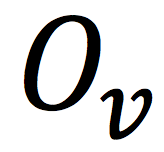
表示训练集的物品集合。
3.2.2 哈希矩阵分解模型
用户和物品的哈希向量表示用户和物品的各自偏好,他们之间的汉明距离表示用户对物品的偏好程度,表示如下:
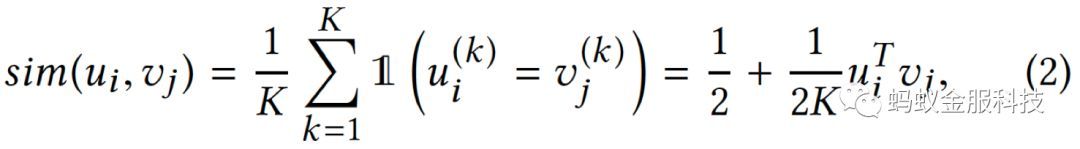
为了学习用户和物品的哈希向量,可以使用以下形式的目标函数:
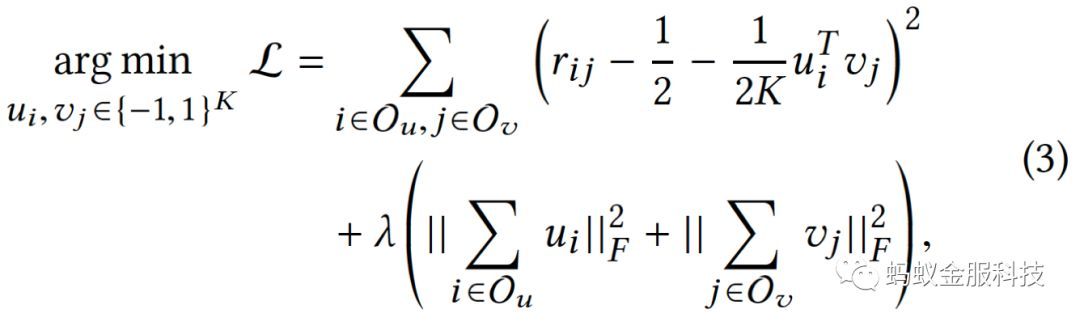
这里,
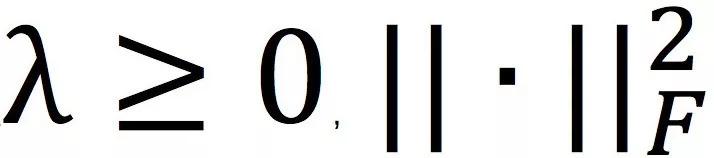
表示Frobenius Norm。以上形式由于
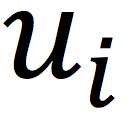
和
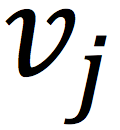
是离散值,很难直接求解。因此,可以采用二步法进行求解[1]。
首先,我们把解空间放松,从原始的
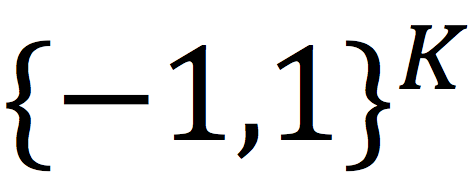
放松到实数空间
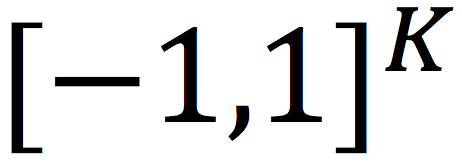
,便可以使用随机梯度下降法求解,梯度如下:
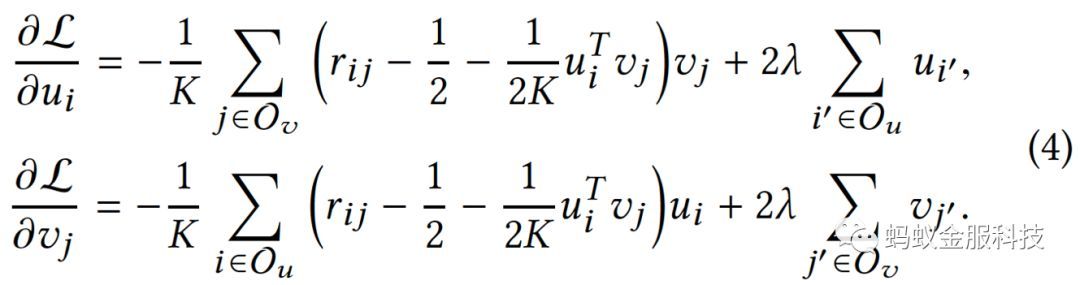
使用随机梯度下降法更新公式如下:

接着,便可以将求解好的实数向量,映射回哈希向量,方式如下:

3.2.3 基于参数服务器用随机梯度下降法进行模型分布式实现
参数服务器的工作理念如下图所示:
这里Coordinator负责模型的调度;Server负责存储及更新模型,这里就是用户和物品的潜在向量
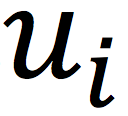
和
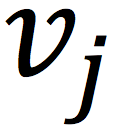
;Worker负责加载数据并求梯度。参数服务器的工作理念可以参见[2]。
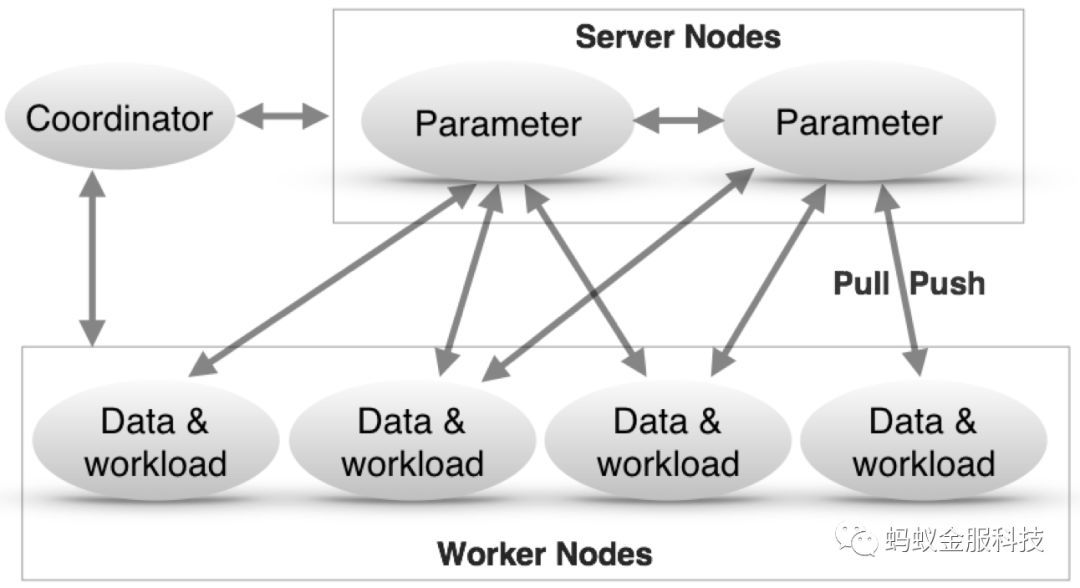
图2:参数服务器架构图
同时,在模型更新过程中,为了防止模型跑飞,我们会在Server上对模型进行修正,方式如下:

这里,
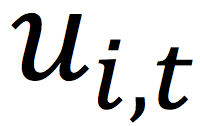
和
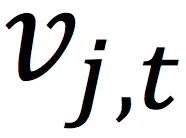
分别表示用户和物品潜在向量在t时刻的值。在实现过程中,我们使用的是阿里和蚂蚁自主研发的鲲鹏分布式学习架构,参见论文[3]。我们的算法名称是Distributed Collaborative Hashing(DCH),整个算法更新的框架如下:

图3

图4
3.3实验结果及分析
我们在公开数据Netflix以及蚂蚁自己的数据Alipay上做了实验,采用DCG和Precision两个评价指标。同时对比了以下几个方法:
- Matrix Factorization (MF) [4]
- MFH,即使用MF得到用户和物品实数潜在向量之后,使用公式(6)映射成哈希向量
- Distributed Factorization Machine (DFM),即使用参数服务器模型实现的[5]
- DFMH即使用DFM得到用户和物品实数潜在向量之后,使用公式(6)映射成哈希向量
几个算法对比结果如下:

图5

图6

图7

图8
从图3和图5中可以看出,我们提出的DCH模型可以达到与现有模型效果相当的结果。从图6可以看出,我们的模型线下训练的时长得到了成倍的缩减,同时从图8可以看出,我们的模型在线上打分上,速度也比使用实数向量的方法有极明显的提升。综合而言,我们的模型通过参数服务器模型,大大降低了线下模型训练时间。同时,我们提出的模型通过牺牲微小的精度,来节省大量的线上打分排序时间。
3.4在蚂蚁的应用
我们提出的DCH方法,可以用于根据用户——物品的行为历史,产出用户和物品的哈希向量,该向量有两个用途:(1)可以直接使用哈希表查找等方式找到与某用户最相似的物品,用于召回或推荐;(2)该哈希向量表示了用户和物品的偏好特征,可以直接作为高阶的特征送到其他模型(如逻辑回归)中使用,进一步提升模型的效果。因此,可以被广泛的应用于蚂蚁的各个推荐场景中去。
3.5参考文献
[1] Ke Zhou and Hongyuan Zha. 2012.Learning binary codes for collaborative filtering. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM,498–506.
[2] Mu Li, David G Andersen, Jun Woo Park,Alexander J Smola, Amr Ahmed, Vanja Josifovski, James Long, Eugene JShekita, and Bor-Yiing Su. 2014. Scaling distributed machine learning with the parameter server. In OSDI. 583–598.
[3] Jun Zhou, Xiaolong Li, Peilin Zhao, Chaochao Chen, Longfei Li, Xinxing Yang, Qing Cui, Jin Yu, Xu Chen, Yi Ding, et al.2017. KunPeng: Parameter Server based Distributed Learning Systems and Its Applications in Alibaba and Ant Financial. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 1693–1702.
[4] Andriy Mnih and Ruslan Salakhutdinov.2007. Probabilistic matrix factorization. In Advances in Neural Information Processing Systems. 1257–1264.
[5] Mu Li, Ziqi Liu, Alexander J Smola, andYu-Xiang Wang. 2016. DiFacto: Distributed Factorization Machines. In Proceedings of the Ninth ACM International Conference on Web Search and Data Mining.ACM, 377–386.
— END —












