 2021-03-22 15:38:50
2021-03-22 15:38:50
在一次做网站的时候 ,需要抓取一些其他网站的新闻 ,在这里介绍一种使用curl通过链接的方式去获取这个页面的所有内容,然后再通过正则匹配获取需要的内容。不是所有网站都能抓取需要有页面规律才能去抓取如下图
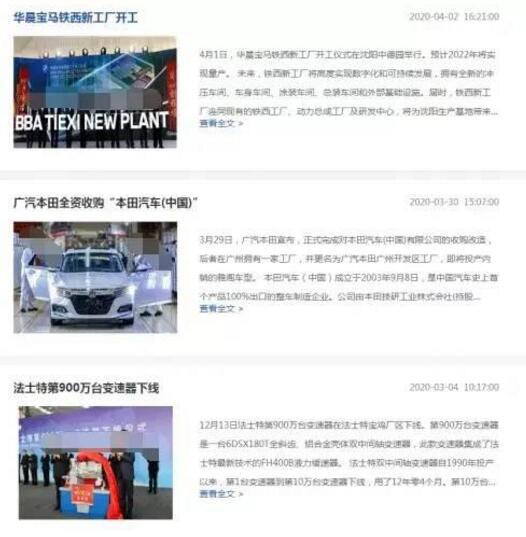
这种有规律的新闻列表 ,不过新闻的详情内容需要再次单独的去抓取,代码:$url = http://xxxx; // https://xxxx要抓取的链接 新闻列表 $url=str_replace('&','&',$url); header("content-type:text/html;charset=utf-8"); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0);//除去https里面的s curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//关闭直接输出 $ html_data =curl_exec($ch); curl_close($ch);//关闭会话这里要确认是否抓取到了页面的内容 可以打印出来看一下如果没有抓取到 要注意一下 页面的编码格式 使用iconv()转换一下内容编码 // $html_data=iconv('gbk', 'utf-8',$html_data); $regular='#<h1id="activity-name">(.*?)</h1>(.*?)<spanid="post-date">(.*?)<span>(.*?)</span>(.*?)<div class="page-content">(.*?)<div class="text">(.*?)</div>#is'; preg_match_all($regular,$html_data,$connect);//进行正规匹配取得自己要的内容 //循环取出需要的内容数组 foreach($connect as $k =>$var){ if($k==2 || $k==3|| $k==5 || $k==7){ $b= array_merge(array_filter($connect[$k])); $array[]=$b; } }得到数据数组后 就可以根据需求去添加数据了内容详情需要抓取就获取到新闻内容页的链接 同样使用curl去获取信息要注意的就是正则表达式里面的html需要跟页面的格式一样, 你可以去原网站点右键查看源代码,查看格式, 把要抓取的html复制下来 ,如果还是有不能抓取的内容可能就是格式不正确 有可能有的地方是少空格或者多空格, 这个时候直接在标签之间(.*?)。也可以 一点一点的匹配 看具体是哪个部分没有匹配到。
下一篇:没有了












