 2021-03-24 08:27:46
2021-03-24 08:27:46
rm(list=ls())options(stringsAsFactors = F)library(Seurat)metadata1 "G:/celllungcancer/S01_metacells.csv", row.names=1, header=T)
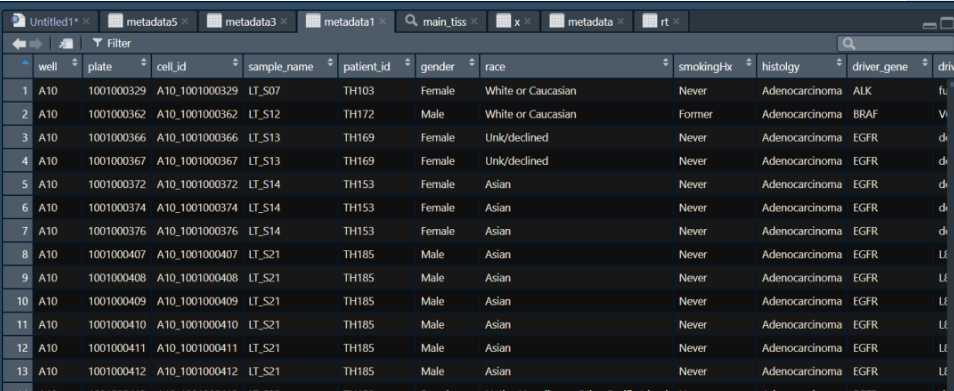
metadata2 "G:/celllungcancer/S01_metacells.csv", header = T,data.table = F)
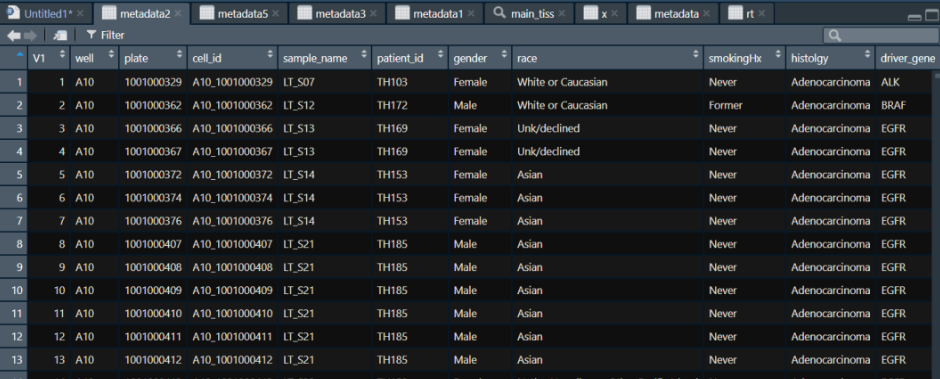
metadata3 <- fread(file ="G:/celllungcancer/S01_metacells.csv", header = T, sep = '\t',data.table = F)

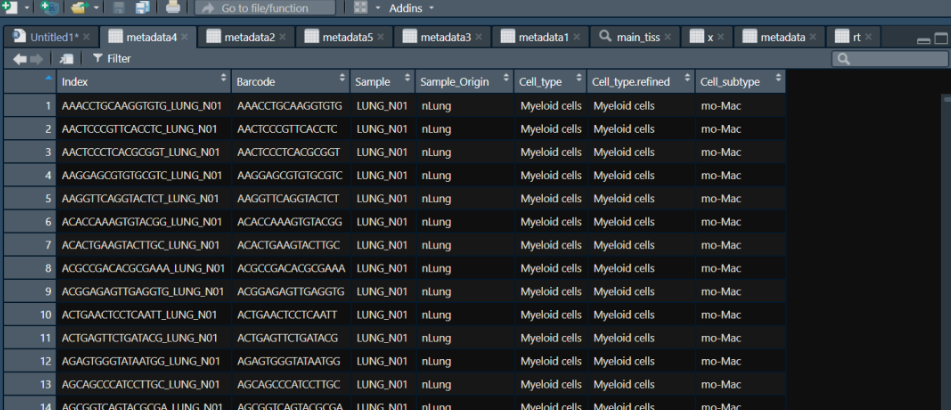
metadata4 <- fread(file = "G:/nature communication/GSE131907_Lung_Cancer_cell_annotation.txt", header = T, sep = '\t',data.table = F)
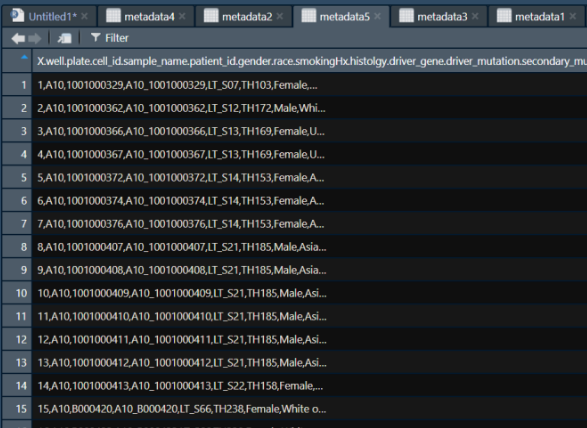
metadata5 <-read.table(file ="G:/celllungcancer/S01_metacells.csv", header = T, sep = '\t')
metadata6 "G:/celllungcancer/S01_metacells.csv", header = T, sep = '\t')
综上,txt和csv文件有本质区别:
txt读取时需要加sep = '\t';
但是csv文件不可以加sep = '\t';
在读取大文件时候 一定要用fread函数,加载library(data.table)。
关于fread函数参数如下:
做基因组数据分析时,常常需要读入处理大文件,这个时候我们就可以舍弃read.table,read.csv等,使用读入速度快的fread函数
fread(input, sep="auto", sep2="auto", nrows=-1L, header="auto", na.strings="NA", file,
stringsAsFactors=FALSE, verbose=getOption("datatable.verbose"), autostart=1L,
skip=0L, select=NULL, drop=NULL, colClasses=NULL,
integer64=getOption("datatable.integer64"),# default: "integer64"
dec=if (sep!=".") "." else ",", col.names,
check.names=FALSE, encoding="unknown", quote="\"",
strip.white=TRUE, fill=FALSE, blank.lines.skip=FALSE, key=NULL,
showProgress=getOption("datatable.showProgress"), # default: TRUE
data.table=getOption("datatable.fread.datatable") # default: TRUE )
input 输入的文件,或者字符串(至少有一个"\n");
sep 列之间的分隔符;
sep2 分隔符内再分隔的分隔符,功能还没有应用;
nrow 读取的行数,默认-l全部,nrow=0仅仅返回列名;
header 第一行是否是列名;
na.strings 对NA的解释;
file 文件路径,再确保没有执行shell命令时很有用,也可以在input参数输入;
stringsASFactors 是否转化字符串为因子;
verbose 是否交互和报告运行时间;
autostart 机器可读这个区域任何行号,默认1L,如果这行是空,就读下一行;
skip 跳过读取的行数,为1则从第二行开始读,设置了这个选项,就会自动忽略autostart选项,也可以是一个字符,skip="string",那么会从包含该字符的行开始读;
select 需要保留的列名或者列号,不要其它的;
drop 需要取掉的列名或者列号,要其它的;
colClasses 类字符矢量,用于罕见的覆盖而不是常规使用,只会使一列变为更高的类型,不能降低类型;
integer64 读如64位的整型数;
dec 小数分隔符,默认"."不然就是","col.names 给列名,默认试用header或者探测到的,不然就是V+列号;
encoding 默认"unknown",其它可能"UTF-8"或者"Latin-1",不是用来重新编码的,而是允许处理的字符串在本机编码;
quote 默认""",如果以双引开头,fread强有力的处理里面的引号,如果失败了就会用其它尝试,如果设置quote="",默认引号不可用strip.white 默认TRUE,删除结尾空白符,如果FALSE,只取掉header的结尾空白符;
fill 默认FALSE,如果TRUE,不等长的区域可以自动填上,利于文件顺利读入;
blank.lines.skip 默认FALSE,如果TRUE,跳过空白行key 设置key,用一个或多个列名,会传递给setkeyshowProgress TRUE会显示脚本进程,R层次的C代码data.table TRUE返回data.table,FALSE返回data.frame。
原文链接:https://blog.csdn.net/weixin_35098081/article/details/112102283
上一篇:mac系统计算器怎么计算面积? mac计算器算面积的技巧
下一篇:没有了












