 2021-11-06 12:07:42
2021-11-06 12:07:42
前言
前段时间我在go上发布了HTTP请求的——HTTP1.1请求流分析,所以打算研究一下这两天HTTP2.0的请求源代码,但是发现太复杂了,于是去访问知乎,然后发现了一个很有意思的问题“golang特殊字符的字符串怎么能转换成[]字节?”。为了改变心情,我有了这篇文章。
问题
我就不码原题了,直接上图:

看到问题,我的第一反应是ASCII码取值范围应该是0~127,怎么可能超过127?直到实际操作才发现上图中的特殊字符是' '(如果不能显示,请记住这个特殊字符的unicode是u0081),这在英语中并不是句号。
unicode和utf-8的恩怨纠葛
百度百科对unicode和utf-8做了非常详细的介绍,这里就不做过多的阐述了,只是摘录一些与本文相关的定义:
Unicode为每个字符(通常用两个字节表示一个字符.)设置了统一且唯一的二进制编码
UTF-8是Unicode的可变长度字符编码。它可以用来表示Unicode标准中的任何字符。UTF-8的特点是对不同范围的字符使用不同的长度代码。对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同.
go中的字符
众所周知,围棋中有两种文字可以表达,即字节和符文。字节和符文的定义分别是:type byte=uint8和type rune=int32。
uint8的范围是0-255,只能表示有限数量的unicode字符。如果范围超过255,将会编译一个错误。根据上面对unicode的定义,4字节的符文与2字节的unicode完全兼容。
我们使用以下代码来验证:
var(
c1字节='a '
C2字节=“新”
C3符文='新'
)
fmt。Println(c1,c2,c3)
复制代码
以上程序根本无法运行,因为第二行编译会给出错误,vscode给出了非常详细的提示:‘new’(无标题Rune常量26032)溢出字节。
接下来,我们通过以下代码验证字符与unicode和整数之间的等价性:
Fmt。Printf('0x%x,%dn ','',' ')//输出:0x81,129
Fmt.println (0x81==' ',' U0081'=' ',129==' ')//输出:真真真真
//u0081输出到屏幕后不会显示,所以输出会用大写字母A。
Fmt。Printf('%cn ',65) //输出:a
复制代码
根据上述代码的三个真实输出,我们可以知道字符和unicode和整形是等价,和塑造也可以转向人物的表现。
go中的字符串是utf8编码的
根据golang官方博客blog.golang.org/strings:的原文
Go源代码始终是UTF-8。
字符串包含任意字节。
没有字节级转义的字符串始终包含有效的UTF-8序列。
复制代码
翻译其实就是两点:
go中的代码总是用utf8编码,字符串可以存储任何字节。
没有字节级转义,字符串是标准的utf8序列。
有了前面的基础知识和字符串是标准utf8序列的结论,我们接下来手动对字符串“”进行编码(如果不能显示,请记住这个特殊字符的unicode是u0081)。
Unicode到UTF-8编码器对照表:
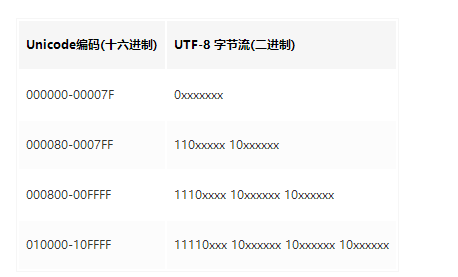
字符“”的二进制表示(如果不能显示,请记住这个特殊字符的unicode是u0081)是10000001,十六进制表示是0x81。
。根据unicode转utf8的对照表,0x7f < 0x81 < 0x7ff,所以此特殊字符需占两个字节,并且要套用的utf8模版是110xxxxx 10xxxxxx。
我们按照下面的步骤对10000001转为utf8的二进制序列:
第一步:根据x数量对特殊字符的高位补0。x的数量是11,所以需要对特殊字符的高位补3个0,此时特殊字符的二进制表示为:00010000001。
第二步:x有两个部分,且长度分别是5和6,所以对00010000001由底位向高位分别截取6位和5位,得到000001和00010。
第三步:将000001和00010由低位向高位填充至模版110xxxxx 10xxxxxx,可得到utf8的二进制序列为:11000010 10000001。
我们通过go对二进制转为整型:
fmt.Printf("%d, %dn", 0b11000010, 0b10000001)
// 输出:194, 129
复制代码综上:当用字符转字节时输出的是字符本身的整型值,当用字符串转字节切片时,实际上是输出的是utf8的字节切片序列(go中的字符串存储的就是utf8字节切片)。此时,我们回顾一下最开始的问题,就会发现输出是完全符合预期的。
go中的rune
笔者在这里猜测提问者期望的结果是“字符串转字节切片和字符转字节的结果保持一致”,这时rune就派上用场了,我们看看使用rune的效果:
fmt.Println([]rune("?"))
// 输出:[129]
复制代码由上可知用rune切片去转字符串时,它是直接将每个字符转为对应的unicode。
我们通过下面的代码模拟字符串转为[]rune切片和[]rune切片转为字符串的过程:
字符串转为rune切片:
// 字符串直接转为[]rune切片
for _, v := range []rune("新世界杂货铺") {
fmt.Printf("%x ", v)
}
fmt.Println()
bs := []byte("新世界杂货铺")
for len(bs) > 0 {
r, w := utf8.DecodeRune(bs)
fmt.Printf("%x ", r)
bs = bs[w:]
}
fmt.Println()
// 输出:
// 65b0 4e16 754c 6742 8d27 94fa
// 65b0 4e16 754c 6742 8d27 94fa
复制代码上述代码中utf8.DecodeRune的作用是通过传入的utf8字节序列转为一个rune即unicode。
rune切片转为字符串:
// rune切片转为字符串
rs := []rune{0x65b0, 0x4e16, 0x754c, 0x6742, 0x8d27, 0x94fa}
fmt.Println(string(rs))
utf8bs := make([]byte, 0)
for _, r := range rs {
bs := make([]byte, 4)
w := utf8.EncodeRune(bs, r)
utf8bs = append(utf8bs, bs[:w]...)
}
fmt.Println(string(utf8bs))
// 输出:
// 新世界杂货铺
// 新世界杂货铺
复制代码上述代码中utf8.EncodeRune的作用是将一个rune转为utf8字节序列。
综上:对于无法确定字符串中仅有单字节的字符的情况, 请使用rune,每一个rune类型代表一个unicode字符,并且它可以和字符串做无缝切换。
理解go中的字符串其实是字节切片
前面已经提到了字符串能够存储任意字节数据,而且是一个标准的utf8格式的字节切片。那么本节将会通过代码来加深印象。
fmt.Println([]byte("新世界杂货铺"))
s := "新世界杂货铺"
for i := 0; i < len(s); i++ {
fmt.Print(s[i], " ")
}
fmt.Println()
// 输出:
// [230 150 176 228 184 150 231 149 140 230 157 130 232 180 167 233 147 186]
// 230 150 176 228 184 150 231 149 140 230 157 130 232 180 167 233 147 186
复制代码由上述的代码可知,我们通过游标按字节访问字符串得到的结果和字符串转为字节切片是一样的,因此可以再次确认字符串和字节切片是等价的。
通常情况下我们的字符串都是标准utf8格式的字节切片,但这并不是说明字符串只能存储utf8格式的字节切片,go中的字符串可以存储任意的字节数据。
bs := []byte{65, 73, 230, 150, 176, 255}
fmt.Println(string(bs)) // 将随机的字节切片转为字符串
fmt.Println([]byte(string(bs))) // 将字符串再次转回字节切片
rs := []rune(string(bs)) // 将字符串转为字节rune切片
fmt.Println(rs) // 输出rune切片
fmt.Println(string(rs)) // 将rune切片转为字符串
for len(bs) > 0 {
r, w := utf8.DecodeRune(bs)
fmt.Printf("%d: 0x%x ", r, r) // 输出rune的值和其对应的16进制
bs = bs[w:]
}
fmt.Println()
fmt.Println([]byte(string(rs))) // 将rune切片转为字符串后再次转为字节切片
// 输出:
// AI新?
// [65 73 230 150 176 255]
// [65 73 26032 65533]
// AI新?
// 65: 0x41 73: 0x49 26032: 0x65b0 65533: 0xfffd
// [65 73 230 150 176 239 191 189]
复制代码仔细阅读上面的代码和输出,前5行的输出应该是没有疑问的。但是第6行输出却和预期有出入。
前面提到了字符串可以存储任意的字节数据,那如果存储的字节数据不是标准的utf8字节切片就会出现上面的问题。
我们已经知道通过utf8.DecodeRune可以将字节切片转为rune。那如果碰到不符合utf8编码规范的字节切片时,utf8.DecodeRune会返回一个容错的unicodeuFFFD,这个unicode对应上面输出的16进制0xfffd。
问题也就出现在这个容错的unicodeuFFFD上,因为字节切片不符合utf8编码规范无法得到正确的unicode,既uFFFD占据了本应该是正确的unicode所在的位置。这个时候再将已经含有容错字符的rune切片转为字符串时,字符串存储的就是合法的utf8字节切片了,因此第六行输出的是含有uFFFD的合法utf8字节切片,也就产生了和最初始的字节切片不一致的情况了。
?:在平时的开发中要注意rune切片和byte切片的相互转换一定要基于没有乱码的字符串(内部是符合utf8编码规则的字节切片),否则容易出现上述类似的错误。
字符串的多种表示方式
本节算是扩展了,在开发中还是尽量别用这种特殊的表示方式,虽然看起来很高级但是可读性太差。
下面直接看代码:
bs := []byte([]byte("新"))
for i := 0; i < len(bs); i++ {
fmt.Printf("0x%x ", bs[i])
}
fmt.Println()
fmt.Println("xe6x96xb0")
fmt.Println("xe6x96xb0世界杂货铺" == "新世界杂货铺")
fmt.Println('u65b0' == '新')
fmt.Println("u65b0世界杂货铺" == "新世界杂货铺")
// 输出:
// 0xe6 0x96 0xb0
// 新
// true
// true
// true
复制代码目前笔者仅发现unicode和单字节的16进制可以直接用在字符串中, 欢迎读者提供更多的表示方式以供交流。












