 2021-11-08 21:52:42
2021-11-08 21:52:42
1 分组聚合的原因
前面关于SQL中分组函数和聚合函数的文章已经介绍过了。简单理解这两个函数是可能的。分组函数是分组依据,聚合函数是计数、最大值、最小值、AVG、总和。
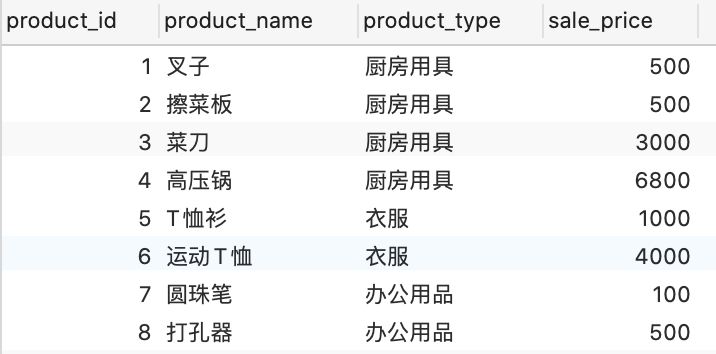
以图中数据为例进行说明,假设数据按照product_type字段分组,分组后的结果如下。
从产品中选择产品类型
按产品类型分组

从图中可以看出,分为三组,分别是厨具、衣服和办公用品,相当于去掉了product_type字段的重复。实际上,按功能分组具有删除重复项的功能。
从产品中选择不同的产品类型
假设分组,我要看价格,也就是字段sale_price的值。根据下面的写法,我将报告下面的错误。
从产品中选择产品类型、销售价格
按产品类型分组

这是为什么?原表按product_type分组后,厨具有4个值,衣服有2个值,办公用品有2个值,这就是为什么选择sale_price字段有错误的原因。您不能在一个空格中填写多个值。此时,您可以使用聚合函数,如求和、平均、最大和最小以及行数。聚合后只有一个值。
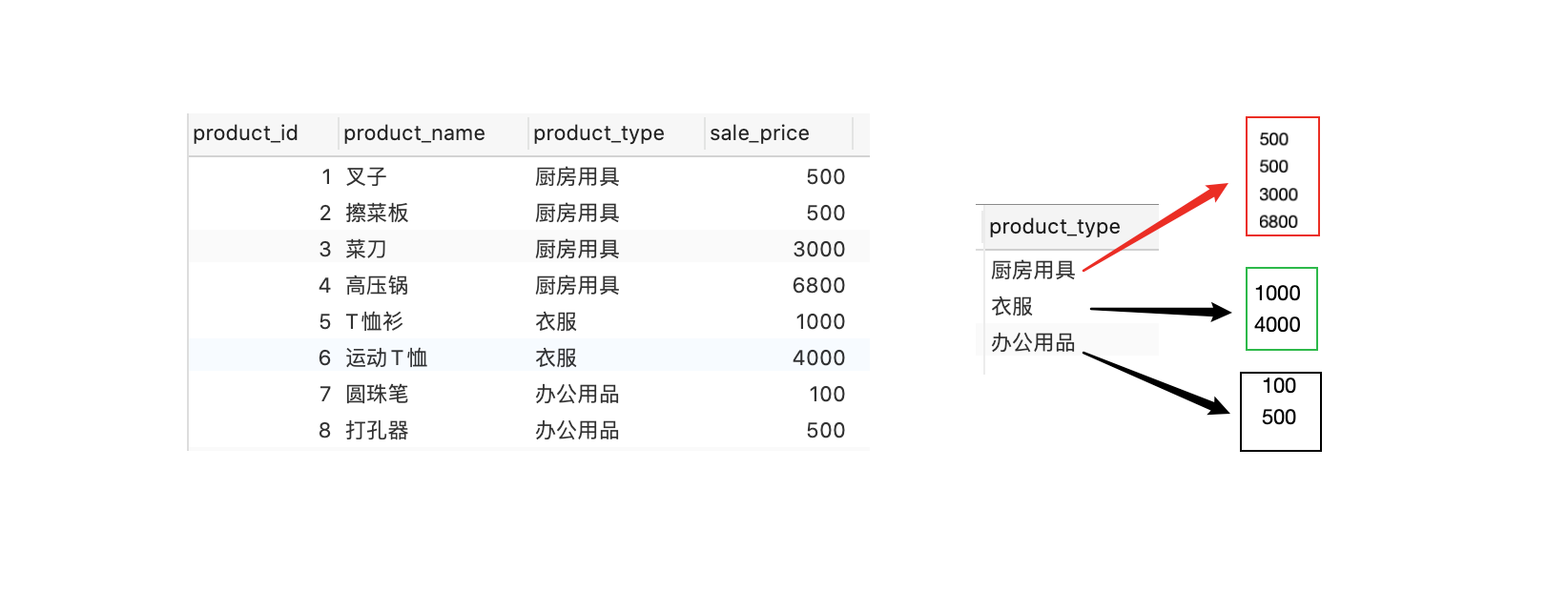
从产品中选择产品类型、总和(销售价格)、平均值(销售价格)、计数(销售价格)、最大值(销售价格)
按产品类型分组

对于分组多个字段,原则是相同的。请记住上面的两点:数据包重复数据消除和数据包聚合。
2 distinct和group by去重的区别
不同的群体有不同的设计重点。
Distinct只是去除权重,而group by是聚合统计。
两者都有重复数据消除的效果,但实现的效率不同。
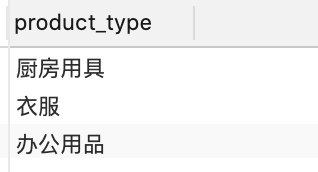
单个字段去重
- DISTINCT
从产品中选择不同的产品类型
-分组依据
从产品中选择产品类型
按产品类型分组
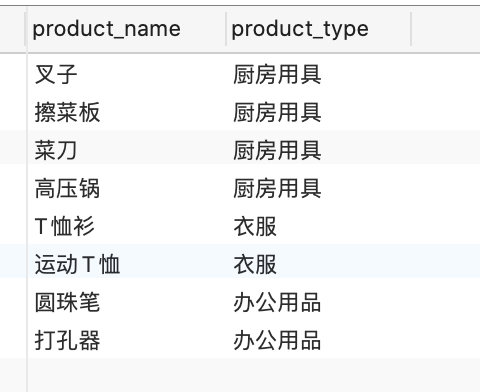
多个字段去重
- DISTINCT
从产品中选择不同的产品名称、产品类型
-分组依据
从产品中选择产品名称、产品类型
按产品名称、产品类型分组
执行效率
选择列名1,列名2
从表名
其中查询条件
按分组类别分组
Having指定对结果进行分组的条件。
按列名排序(desc)
限制数量

SQL语言的运行顺序,先执行上图第一步,再执行select子句,最后过滤结果。Distinct在select子句中,group by是第一步,因此group by重复数据消除比distinct重复数据消除更有效。












