 2020-03-13 22:49:35
2020-03-13 22:49:35
在视频成为重要媒介,vlog、视频博主也成为一种职业的当下,如何提高自己视频的播放量,是广大内容生产者最头秃的问题之一。网络上当然有许多内容制作、热点跟踪、剪辑技巧的分享,但你可能不知道,机器学习也可以在其中发挥大作用。
join into data上两位作者 Lianne 和 Justin 做了一个硬核的技术分析。他们的分析对象是 YouTube 一个新近崛起的健身博主 Sydney Cummings 。
Sydney 拥有美国国家运动医学会(NASM)的私人教练证,同时也是一位跳高运动员。她的账号注册于 2016 年 5 月 17 日,累计播放量 27,031,566,目前拥有 21 万粉丝,每天都稳定更新,很有研究意义。请注意,以下研究都将通过 Python 实现。
Sydney Cummings 的标题都有一定套路,比如最近一个标题是《30 分钟手臂和强壮臀肌锻炼!燃烧 310 卡路里!》,通常涵盖时间、身体部位、消耗的卡路里以及其他关于锻炼的描述性词汇。观众点击这段视频之前,就会知道几个信息:
-
30 分钟——我将在 30 分钟内完成整个训练;
-
锻炼手臂和臀肌——我将致力于手臂和臀肌,专注于力量;
-
燃烧 310 卡路里——我会燃烧相当多的卡路里。
掌握以上关键信息是预先的准备,接下来还有六个步骤:观察数据、用自然语言处理技术对视频进行分类、选择特征、创建目标、构建决策树、阅读决策树。接下来就和雷锋网一起看看作者究竟是怎么一步一步展开研究的。
事前准备:抓取数据
其实有很多不同的方法来抓取 YouTube 数据。由于这只是个一次性项目,所以作者选择了一个只需要手工操作,不依赖额外工具的简单方法。
以下是分步步骤:
选中所有视频;
右键单击最新的视频并选择“Inspect“;
将光标悬停在每一行上,找到高亮显示了所有视频的最低级别的 HTML 代码/元素级别;
例如,如果使用 Chrome 浏览器,它看起来就像这样:
【 图片来源:Sydney’s YouTube Video page所有者:Sydney 】
右键单击元素并选择“复制”,然后选择“复制元素”;
将复制的元素粘贴到文本文件中并保存,这里使用 JupyterLab 文本文件并将其保存为 sydney.txt;
使用 Python 提取信息并清理数据。
接下来就是有趣的部分了,他们将从这个数据中集中提取特征,并研究是哪些因素影响着播放量。
步骤 1:观察数据
将数据导入到 Python 中是在最后一节中完成的,以下是数据集 df_videos,一共有 837 个视频。
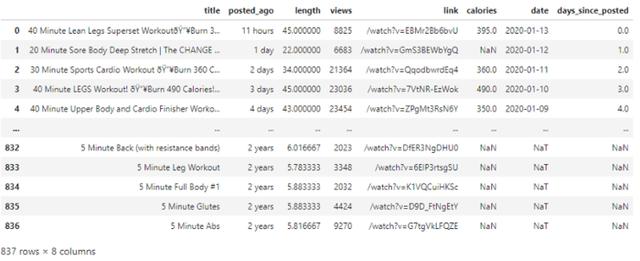
df_videos 有 8 个特征来描述每个视频细节,包括:标题、多久前发布的、视频长度、播放量、地址、卡路里、发布具体日期、发布至今的天数。
此外,他们注意到数据有重叠,因为博主曾经多次上传同一个视频,在接下来的分析中将会忽略这部分不大的样本。
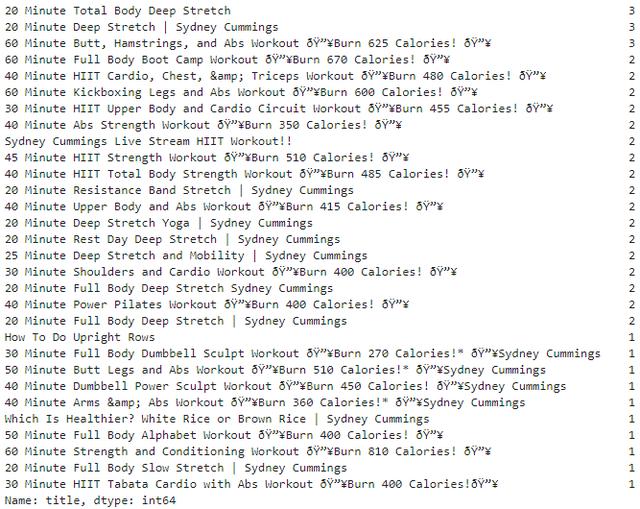
步骤 2:用 NLP 对视频进行分类
在这一步中,他们根据标题中的关键词对视频进行分类。
分组标准是:
-
这个视频针对的是身体哪个部位?
-
这个视频的目的是增肌还是减肥?
-
或者还有什么其他关键词?
作者使用了自然语言工具包(NLTK),Python 中一个常用的开源 NLP 库,来处理标题。
生成关键词列表
首先,标记化视频的标题。此过程使用分隔符(如空格(" ")将标题文本字符串拆分为不同的标记(单词)。这样,计算机程序就可以更好地理解文本。
这些标题中有 538 个不同的单词,以下列出了使用频率最高的标记/单词。可以发现,频繁使用的就是那几个词,这也再次证明博主确实喜欢起标准格式的视频标题。












