 2020-04-15 19:29:28
2020-04-15 19:29:28
从“自给自足”的To C模式,到企业之间互联互通的To B模式,再到金融、医疗、安防全场景应用的过程。
联邦学习,无疑是当前最受工业界和学术界关注的人工智能研究方向之一。
近两年,在杨强教授等世界级专家的联合推动下,国内外多数科技巨头,均已开始搭建联邦学习的研究与应用团队。
基于此,雷锋网《AI金融评论》与《AI科技评论》联合邀请五位顶尖联邦学习专家,启动《金融联邦学习公开课》。其中在昨日的首节公开课上,微众银行首席AI官杨强教授分享了联邦学习前沿与应用价值讨论。(课程全文与视频回顾,将在公众号AI金融评论发布)
今天,我们先来完整回顾下联邦学习诞生三年来,从“自给自足”的To C模式,到企业之间互联互通的To B模式,再到金融、医疗、安防等全场景应用的过程。
联邦学习的诞生:一个有趣的To C设想
联邦学习的概念,首次提出是在2017年的一篇Google AI Blog博文。
文章作者之一是Blaise Aguëray Arcas,他2014年加入谷歌,此前在微软任杰出工程师。加入谷歌后,Blaise领导了谷歌设备端on-device机器智能(Machine Intelligence)项目,同时负责基础研究与新产品研发工作。
在他加入谷歌后不久,便开始了联邦学习的研究。直到2017年,当他们取得了一定的成果,才在博文中进行公布。
设备上的联邦学习
Blaise 等人(或许也在某种程度上代表谷歌)所关注的,更多是设备上的联邦学习——这也正是联邦学习概念被提出之初的应用场景。
由于神经网络仍然受到学习效率的限制,它需要大量的数据进行训练,所以一些大公司,如谷歌、微软、亚马逊等开始提供人工智能服务时需要收集大量的数据,才能去训练大型神经网络。这也是一直以来,整个社区所做的事情。
对于设备端(例如手机)的智能应用,通常情况下的模式是,用户在设备上产生的数据会被上传到服务器中,然后由部署在服务器上的神经网络模型根据收集到的大量数据进行训练得到一个模型,服务商根据这个模型来为用户提供服务。随着用户设备端数据的不断更新并上传到服务器,服务器将根据这些更新数据来更新模型。很明显这是一种集中式的模型训练方法。
然而这种方式存在几个问题:1)无法保证用户的数据隐私,用户使用设备过程中产生的所有数据都将被服务商所收集;2)难以克服网络延迟所造成的卡顿,这在需要实时性的服务(例如输入法)中尤其明显。
Blaise等人便想,是否可以通过做一个大型的分布式的神经网络模型训练框架,让用户数据不出本地(在自己的设备中进行训练)的同时也能获得相同的服务体验。
解决之道便是:上传权重,而非数据。
我们知道神经网络模型是由不同层的神经元之间连接构成的,层与层之间的连接则是通过权重实现的,这些权重决定了神经网络能够做什么:一些权重是用来区分猫和狗的;另一组则可以区分桌子和椅子。从视觉识别到音频处理都是由权重来决定的。神经网络模型的训练本质上就是在训练这些权重。
那么Blaise提出的设备端联邦学习,不再是让用户把数据发送到服务器,然后在服务器上进行模型训练,而是用户本地训练,加密上传训练模型(权重),服务器端会综合成千上万的用户模型后再反馈给用户模型改进方案。
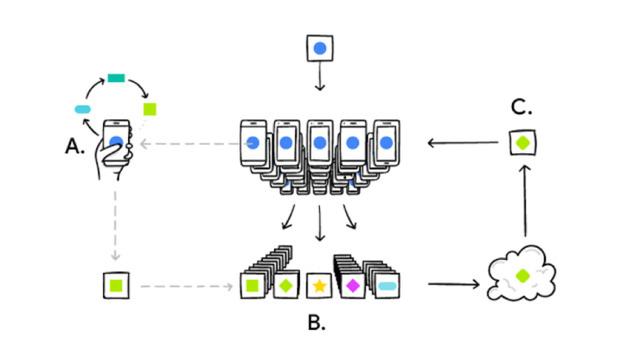
这里或许值得强调,这种在设备端上的模型是经压缩过的,而非像服务器中那种大型神经网络模型。因此模型训练的耗能是非常小的,几乎检测不到。
此外,Blaise讲了一个非常形象的比喻,即人会在睡觉的时候通过做梦来更新自己的大脑认知系统;同样设备终端的系统也可以通过闲置时进行模型训练和更新。所以整体上,这并不会对用户的使用体验造成任何影响。
总结一下设备上联邦学习的过程:
- 设备端下载当前版本的模型;
- 通过学习本地数据来改进模型;
- 把对模型的改进,概括成一个比较小的更新;
- 该更新被加密发送到云端;
- 与其他用户的更新即时整合,作为对共享模型的改进。
整个过程有三个关键环节:
- 根据用户使用情况,每台手机在本地对模型进行个性化改进;
- 形成一个整体的模型修改方案;
- 应用于共享的模型。该过程会不断循环。
其优点显而易见:
首先,数据可以不上传云端,服务提供商看不到用户数据,这能提高用户数据隐私性。因此也就不必在隐私和功能之间权衡,可以两者兼有。这一点在当下数据隐私越来越受到重视的情况下特别重要。
其次,延时降低。如果将用户所有数据都上传到云端,且服务本身也是从云端进行反馈,那么在网速较慢的环境下,网络延时将会极大降低用户体验。而联邦学习加持下的服务则不会出现这种情况,因为服务本身就来自于本地。
同时,联邦学习的出现,也使得用户从人工智能的旁观者,真正转变为人工智能发展的参与者。To B人工智能的困局:
隐私保护、小数据、数据孤岛
其实Google的联邦学习,并没有解决企业之间数据孤岛问题。
Google的方案可以理解为To C的,应用在用户的手机端,是同一家公司根据内部对To C业务的需求所产生的一套用以解决数据隐私问题的方案。
而杨强教授牵头建设的联邦学习生态更多是To B模式,用以解决企业与企业之间的数据孤岛难题,是一个更开放的类似企业联盟的生态。
总体而言,Google的联邦学习方案是横向的,它使用的数据特征相同,因此只需要建同一个模型。
而新方案则是纵向联邦学习,不同企业之间的数据特征往往不同,所以即便面向的用户是相同的场景,整个技术方案和实施框架也不一样。
杨强教授曾在雷锋网承办的CCF-GAIR 2019「AI 金融专场」的大会报告中指出,利益驱使下,各家公司们过去并不愿意把数据拿出来和其他公司交换。除了少数几家拥有海量用户、具备产品和服务优势的「巨无霸」公司外,大多数企业难以以一种合理合法的方式跨越人工智能落地的数据鸿沟,或者对于他们来说需要付出巨大的成本来解决这一问题。
此外,监管当局已经采取颇为严格的隐私保护措施。
去年5月份欧洲首先提出数据隐私保护法GDPR,对人工智能机器的使用、数据的使用和数据确权,都提出非常严格的要求,以至于Google被多次罚款,每次金额都在几千万欧元左右。
因为GDPR其中一则条文就是数据使用不能偏离用户签的协议,也许用户的大数据分析,可以用作提高产品使用体验,但是如果公司拿这些数据训练对话系统,就违反了协议。如果公司要拿这些数据做另外的事,甚至拿这些数据和别人交换,前提必须是一定要获得用户的同意。
另外还有一些严格的要求,包括可遗忘权,就是说用户有一天不希望自己的数据用在你的模型里了,那他就有权告诉公司,公司有责任把该用户的数据从模型里拿出来。这种要求不仅在欧洲,在美国加州也实行了非常严格的类似的数据保护法。
中国对数据隐私和保护也进行了非常细致的研究,从2009年到2019年有一系列动作,而且越来越严格,经过长期的讨论和民众的交互,可能近期会有一系列正式的法律出台。
其次,我们的数据大部分是小数据:没有好的模型就无法做到好的自动化,好的模型往往需要好的大数据,但往往高质量、有标签的数据都是小数据。
而且数据都在变化,每个阶段的数据和上一个阶段的数据有不同的分布,也许特征也会有不同。实时标注这些数据想形成好的训练数据又需要花费很多人力。
当前,大多数应用领域均存在数据有限且质量较差的问题,在某些专业性很强的细分领域(如医疗诊断)更是难以获得足以支撑人工智能技术实现的标注数据。
三是“对抗学习”的挑战。即针对人工智能应用的作假,比如人脸识别就可以做假,针对面部进行合成。如何应对这种“对抗学习”的挑战,这是金融场景下人工智能安全领域的重大题目。
不仅金融场景,在法律场景也是这样,医疗场景更是如此。每个医院的数据集都是有限的,如果不能把这些数据打通,每个数据集就只能做简单的模型,也不能达到人类医生所要求的高质量的疾病识别。
在这样的困境中,不少人觉得人工智能的冬天也许又一次到来了——但在联邦学习研究者看来,这正是一次技术跃迁的良机。
上一篇:产业科技创新中心的概念和特征












